If you’re interested in applying for a role at Canonical, it can help to have some insider guidance.
A lot has been written on social media about Canonical and our hiring processes. Some of it is even true.
I share responsibility for what we do, because I am a hiring lead at Canonical.
Hiring leads are drawn from disciplines across the organisation, each with oversight of one or more hiring pipelines. I’m a Director of Engineering (in Engineering Excellence, where I lead Canonical’s documentation practice). I’m currently involved in the hiring process for various different roles: technical authors, and engineers in Community, Developer Relations and web platform engineering.
I’ve been a hiring lead for several years, and have shepherded dozens of new team members through our hiring process, from their initial application to their contract. Being a hiring lead is a reasonably substantial part of my work.
Some context
Canonical employs about 1300 people around the world. Between 2021 and 2025 we more or less doubled in size.
Each year, we hire between three and four hundred people, and we receive around one million job applications. You can do the maths yourself, but don’t jump to hasty conclusions. (It doesn’t mean that someone who applies has a one in 3000 chance of getting the job, for example). Clearly though, competition for jobs at Canonical is high. For some of our roles it’s exceptionally high.
If you’re inclined to see hiring as a kind of contest between employer and candidate – parties on opposite sides of the table, with opposing interests – you might judge that more competition is excellent for us, but not so great for the candidates. I think it’s not nearly as simple as that.
Amongst all these applications we see: candidates who apply for wholly unsuitable roles; candidates who don’t apply for the job that would suit them best; strong candidates who put in weak applications; candidates who unwittingly undermine their own applications. And we know there are also people, who would be excellent candidates, who decide not to apply at all.
When this happens, it certainly hurts the candidate, but it’s bad for us too. We’d like to change some of those patterns – hence this article, which points out how they occur. We want candidates to avoid some pitfalls and find better success.
Applying for the right job
It’s very hard to get any job if you’re not applying for the right ones. One thing that definitely does not work (not just at Canonical, but anywhere) is spraying applications at the employer.
“Let us do it for you!”
There are online services that make multiple automated applications to many different roles on your behalf. All you have to do is provide your details, and they will do the rest, even cleverly adapting your information to suit the roles they apply for.
Sadly, the one secret that these companies don’t want you to know is that this is a first-class way to get yourself permanently blocked – employers really do not want to be spammed with job applications. The services make applications for unsuitable roles, and put in low-quality applications that would never be considered appropriate anyway.
Don’t use these services. They are not on your side and they do not help you.
What it looks like from our side
When a candidate makes multiple applications, it tells a story.
The story can make good sense. If someone applies for both a Developer Relations and a Community position, the skills and qualities demanded in those roles have a lot of overlap. Similarly, a candidate might apply for a Senior Engineer and a Manager role related to a particular product: also perfectly understandable. Those applications show where the candidate’s interest lies, and there is no problem in putting in applications for more than one role in that way.
On the other hand, someone who applies for five or seven completely unrelated positions is not showing focus. Inevitably, each one of those applications is weak, but one glance at the list of applications as a whole also shows that the candidate doesn’t really understand what the jobs are about, and doesn’t have a strong idea about what they have to contribute.
“I haven’t thought that deeply about what any of these positions entail – I’m just hoping for a job” is not a good signal to send an employer.
Do your research
Don’t start by making an application for the first role that seems remotely plausible. We have hundreds of open roles, so it’s likely that the first one you’ll find is not the best fit.
If you’re an experienced software professional, you can be expected to know how the industry works. You should be able to read job descriptions and understand how what they ask for matches what you can offer. You already have an advantage of understanding in that case: use it to set yourself one step ahead of the candidates who don’t.
Doing research doesn’t mean taking a cursory look at requirements and ticking them off when a word matches: Python: yes, Agile: yes, Kubernetes: yes. It means understanding what is actually needed, and articulating how you will be able to contribute – which is one of the things we look for.
When looking at job descriptions, don’t ask yourself “Do I fit this?” as if you were an interchangeable for a machine. Your question should be: “How could I make a real difference here?”
Opportunities for early-career candidates
The candidates with less industry experience are often the ones who succumb to the temptation of firing off multiple indiscriminate shots in the hope that one hits a target.
One thing you can do is to look specifically for graduate and associate roles, such as Graduate Software Engineer. Here, you don’t need to worry that you will be competing against candidates with many more years of experience than you have, and you can concentrate on what you do have to offer.
We also have general roles, that are open at all levels, as in our advertisement for Python Engineer. We’re not looking for a Python engineer – we’re looking for many Python engineers, for multiple positions, at all levels of seniority (which is exactly what it says in the advertisement).
“All levels” genuinely means all the way from graduate-level to industry-leading experts. We aim to build rational, balanced software teams that give people opportunities to progress – so we need to hire engineers at all those levels.
What we consider outstanding in a junior engineer is not the same as outstanding for a senior. They’ll be assessed appropriately. A senior is expected to demonstrate substantial industry achievement. That can’t be expected of someone at the start of their career, so we’ll look for other demonstrations of ability, that make them stand out amongst their peers.
We’ll help too
One thing you should be aware of: hiring leads at Canonical talk to each other regularly, and are on the look-out for candidates who might be good for other roles. If an intriguing candidate comes into one of my hiring pipelines, but doesn’t seem quite right right for the role they applied for, I will circulate the application to colleagues in charge of more suitable ones.
Many of the candidates I have hired didn’t apply for the job they eventually got. Another hiring lead recognised their potential, and asked me to have a look at them for one of my roles.
Needless to say, this happens only with candidates who have really put themselves into an application in the first place – not the ones who submitted multiple low-effort applications.
When we recognise that we have found someone who is going to be excellent, we can spend our energies looking for the role to suit them, rather than the other way round. (In really exceptional cases, we have even found a candidate and then created a role for them.)
Being outstanding
Usually with a little effort you can show whether you’re a plausible fit for a role, but it’s still only half of what you need to do. For each open position, we have many candidates who fit very well. They will all earn consideration. However, what we are looking for is the ones who really stand out. You need to demonstrate how you stand out.
It’s true that some things that make a candidate stand out are beyond your control – you can’t help it if another candidate is the leading industry contributor to the open source technology the job focuses on, and you are not. But you can take care of the others.
Think about values such as initiative, leadership, commitment, motivation, courage, ambition, technical excellence, persistence, community, responsibility.
Which do you think are most important for the role you’re interested in? What are the job descriptions and interviewers talking about? Get into the habit of thinking about yourself through the lens of outstanding qualities, and to ask yourself whether people see you that way, and why.
Many candidates could do a much better job of showing how they stand out. If you can find a way to do that, you have an immediate advantage.
Being specific
You can only stand out if you say specific, concrete things.
If you read in the job description that you need to have familiarity with relational databases such as Postgres and MysQL, and you note in your application that you are “familiar with relational databases such as Postgres and MySQL” that is fairly useless. It is completely generic.
Tell us what you did with Postgres (or MySQL): “I decided to use PostGIS, and migrated the cluster from the cloud to our own infrastructure” shows us something meaningful, and interesting, about you and databases.
Our questions
The questions we ask in the hiring process are aimed both at establishing how well you fit, and how well you stand out. It’s relatively straightforward for us to determine how well a candidate fits, but what makes a candidate stand out can be harder to see – especially if the candidate themselves has effaced what they could have shown clearly.
At every stage in our hiring process, we ask multiple questions to help you show how you excel in the ways we are looking for. Some candidates seem to regard them with suspicion: each one a trap being set, to catch them out. They answer them as though they were knocking a ball back across a net. Don’t do that. Those questions are there for you. They show you what we want. They are handholds, not traps. We ask many, so that if one of them is a miss for you, you still have other opportunities to demonstrate excellence.
Look for opportunities to use our questions as your springboard to show how you stand out.
Showing and not saying
The important thing in demonstrating how you stand out is exactly that: showing.
All too often candidates rely simply on saying (I am committed; I am passionate; I am expert; I am a fast learner; I take initiative; I can drive projects to their conclusion). That doesn’t help them, or us. Anyone can say those things (and they often do, whether they actually have those qualities or not).
What we want to know is how you can demonstrate the skills, values and qualities we’re looking for.
What achievements, results, awards, efforts can you point to that show them, in your your career, studies or life? How can you tell your stories in a way that someone else understands them, and connects them to what they are looking for? What specific examples and instances tell your story for you?
In an interview, would you know what to talk about if you were asked about them?
A good rule of thumb is that if what you want someone to know is a fact (having been a Python engineer for six years) then saying it is fine. But if it’s about a claim of value (being a Python web technology expert) you need to be able to point to something that actually demonstrates it.
Be prepared
Thinking about this when you’re faced with a question in an interview is much too late. Once again, don’t come passively to the application process, expecting interviewers to discover what they need from you. You have a part to play in it too, that starts long before you apply.
Think about what it is you want to show. Think forwards, to what interviewers will want to know and to how you can show it.
What you are preparing for is your performance in your interview. That’s not performance as in a stage show that impresses an audience with flashy tricks. Nobody wants to hear slick, well-rehearsed speeches in an interview. But, athletes and musicians who understand what needs to be delivered and know they’ll get one chance to do it also rehearse. They think and work through the coming situation in advance, and that is what you must do too.
I’ve heard people advise “just be yourself in the interview”. That is atrocious advice. Don’t just be yourself. You are not a sample of cloth being submitted for inspection by an expert, you are a person taking part in determining how the future is going to be. Be the person you are going to be if you get the job.
Preparedness is one of the qualities you need to be successful at work: demonstrate it in your interviews, by being prepared.
The written interview
We help you prepare for your interviews, through our written interview. (Ironically Canonical’s written interview is an aspect of the hiring process that attracts the most ire from some quarters.)
I have written more about the written interview previously, but in brief, our written interview helps candidates prepare for successive rounds by showing clearly what we care about, and how we hope a candidate will demonstrate excellence.
It is particularly valuable for less experienced candidates, but all candidates benefit from being prompted to think in ways that help them articulate the things that later interviewers will be looking for. An interview in written form gives candidates a chance to show how they stand out, with time to think about it, without the pressure of having to do it on the spot.
One of the effects of the written interview is that it promotes applicants from under-represented backgrounds. Often, someone’s excellence is not immediately visible, especially when that person comes from outside the industry. The written interview is a more open invitation to demonstrate qualities of excellence that might only be hinted at within the tight constraints of an application form or CV.
Success in the written interview
People are entitled to their opinions about our written interview. If someone chooses not to do it, for whatever reason, that is fair enough.
What is harder to understand is when a candidate submits a written interview and clearly resents having done so. It’s very easy to pick this up from the tone and the way questions are answered; it never helps, and it would have saved a lot of everyone’s time not to do it at all.
If you are going to complete a written interview, approach it constructively. That doesn’t mean being uncritical or passive. It’s not an information-gathering exercise, but a series of prompts for you to set out yourself and the qualities you can demonstrate.
Treat each question as a pointer to what we want, and each answer as an opportunity to show value you could deliver. You should ask yourself why certain questions are being asked: What does this question reveal about Canonical’s priorities? Why do they care about this? What is the context?
Maybe you can see something a question should have asked but didn’t. Maybe you have something to say that isn’t precisely what’s being asked. Being a critical, active participant in the written interview means finding a way to connect those with what it’s asking.
You might feel that a question actually gets something wrong. Some candidates are able to articulate their disagreement, in an effective and good-humoured way, while still being able to work with it and delivering what’s required.
If you are able to do that too you will have demonstrated – without even mentioning it – one of the most valuable skills a person can ever bring to work.
Academic excellence
Of all the questions asked in our hiring process, the ones that raise the most eyebrows are the ones about your education. “Why does Canonical care about my high-school results from 30 years ago? What possible relevance does that have to my skills now?”
We don’t hire skills. We hire people, with personal qualities. They are a whole package. We ask about academic attainment on the basis that it – all the way back to school days, even for a candidate later in life – is a strong indicator of many personal qualities and abilities, including performance at work.
The way we approach education allows us to be more flexible and nuanced about it. For example, we don’t insist on degrees in particular subjects. In fact, we don’t require a degree at all. We can look into more, and different, aspects of a candidate’s history.
Your degree
Nearly everyone we hire does in fact have a degree (not just a degree, a good degree). It’s rare when someone doesn’t have a degree. They must still otherwise be able to show outstanding academic results in their high school studies as evidence of excellence, and we will look further, to find a compelling story for the path taken. But, because we look at the whole picture, and because we get more information from candidates, we can and occasionally do hire someone without a degree.
How did you stand out at school?
We hire people from all over the world, from completely different backgrounds, who have negotiated utterly different education systems.
It’s not fair to compare a candidate from a background of social and economic privilege, and who graduated from a top technical university in a wealthy country with a candidate from the other side of the world, who lacked those privileges, and whose opportunities were limited by the circumstances of their birth and their society.
But, if you believe that talent, excellence and determination to succeed can be found everywhere in the world and in people of every background, it is fair to ask: “Amongst your peers, at school amongst people from your background, who shared similar circumstances and opportunities – how did you stand out?”
Demonstrating excellence
We look for demonstration of academic excellence as part of our hiring process. It matters for senior roles as well as for entry-level positions, and for candidates of all ages.
If you are interested in working at Canonical you need to answer the questions we ask. If you’re going to be successful you need to answer them well: sincerely, strongly and clearly.
Someone who can show outstanding results has an advantage in the hiring process. Someone whose academic story is one of weak ambition and poor achievement is not going to find a role at Canonical.
Nothing is being hidden here. The questions – like them or not – transparently show what we seek.
As in all other aspects of your application, we are looking for excellence. You need to be able to demonstrate it. We ask further about it at different stages, and it quickly becomes apparent if someone’s claims don’t add up.
People are entitled to have opinions about this. It’s reasonable for them to ask questions about it. Many do, in their interviews, and we are happy to have a conversation about it.
If someone decides they don’t want to discuss their education or answer our questions, for whatever reason, that is fair enough. There are plenty of other companies offering jobs, and we have plenty of other candidates. But, it would be a shame if an otherwise strong candidate withdrew an application on the basis of unfounded fears about the purpose of those questions.
AI and LLMs
We don’t employ LLMs at Canonical, we employ human beings. We don’t want LLMs to apply for jobs, and we ask candidates not to use them in their applications.
Some candidates do it anyway – and then it’s usually obvious when they do, because the patterns of AI are so recognisable.
It’s good to quantify claims, but we’ve received CVs saying things like “Streamlined data retrieval and analysis across multiple platforms by 40%” or “Improved development process efficiency by 17%”. This is just gibberish with numbers in it; what it tells us is that the candidate has not even thought about what they expect other people to read.
The written interview is a candidate’s opportunity to show who they are, but AI turns writing into a kind of characterless blended soup, with all the personality washed out of it. It makes for grim reading: generic claims without any ring of truth.
The only thing worse is when someone has asked an LLM to inject “personality” into what they write. It’s instantly obvious, and a miserable experience for the reviewer.
Don’t let AI erase your personality, or make you look false, or silly. Candidates turn to AI to help them, but the result is not what they hope. There is no way to stand out as excellent when you have relied on an LLM to present you in the application process.
We don’t use AI
Job applicants who fear that their application will be evaluated by AI sometimes resort to keyword-stuffing in the hope they will pass that hurdle and get to encounter a human.
We don’t use AI. Hiring needs to be fair, and the risk is that LLMs could recapitulate and reinforce already-hidden biases in hiring. An LLM could never for example have the context or motivation of a human hiring lead, excited by a candidate from an unusual background, eager to see if a suitable role could be found for them.
Perhaps you have read the advice that you need to make sure your application and CV mention all the keywords in the job advertisement. Ignore that advice. Your application will not be read by a pattern-matching algorithm. It will go into the hands of an intelligent human being, who has domain knowledge, who cares, and makes human judgements.
Be a human
Apart from some very simple automation, you and your application are handled entirely by humans. Be a human. Write for humans. They will thank you in turn for being a human being. (They will also make human mistakes sometimes.)
I want to help you to help us to help you
I hope this article helps someone.
Just like my hiring lead colleagues, I know perfectly well that a job application doesn’t give us a wholly reliable picture of the candidate, and the candidate we encounter doesn’t always represent the person who actually joins us in the company. Both applying for jobs and hiring people for them are difficult sciences.
Still, one of the greatest frustrations of my role is a candidate whom I suspect, or even know, is much stronger than their performance in the hiring process suggests.
In those cases I would love to probe further and discover whether I’m right, but I deal with my fair share of our one million applications each year, and it’s not possible for me to do that every single time. I have other candidates to take care of too, and the ones who are excellent and have shown it effectively in their applications will get my attention first.
I hope this article reaches the ones who are excellent, but need some help in understanding how to demonstrate it. If you believe you have excellence to show, and can see a role at Canonical in which you could be an outstanding contributor – apply for it.
My hiring lead colleagues and I need you to help us see how you stand out. Doing that will be your surest route to success in a job application at Canonical, and it’s how we are going to recruit the outstanding new colleagues we seek.


 Mariam enjoying Cape Town’s waterfront during a team outing at a work sprint in South Africa.
Mariam enjoying Cape Town’s waterfront during a team outing at a work sprint in South Africa.
 Simple command-line interface
Simple command-line interface Secure API key and model management with
Secure API key and model management with  Clean output (only the AI response, no JSON clutter)
Clean output (only the AI response, no JSON clutter) Natural language queries
Natural language queries Uses free Mistral model by default
Uses free Mistral model by default Stateless design – each query is independent (no conversation history)
Stateless design – each query is independent (no conversation history)


 Stay Connected with the Community
Stay Connected with the Community
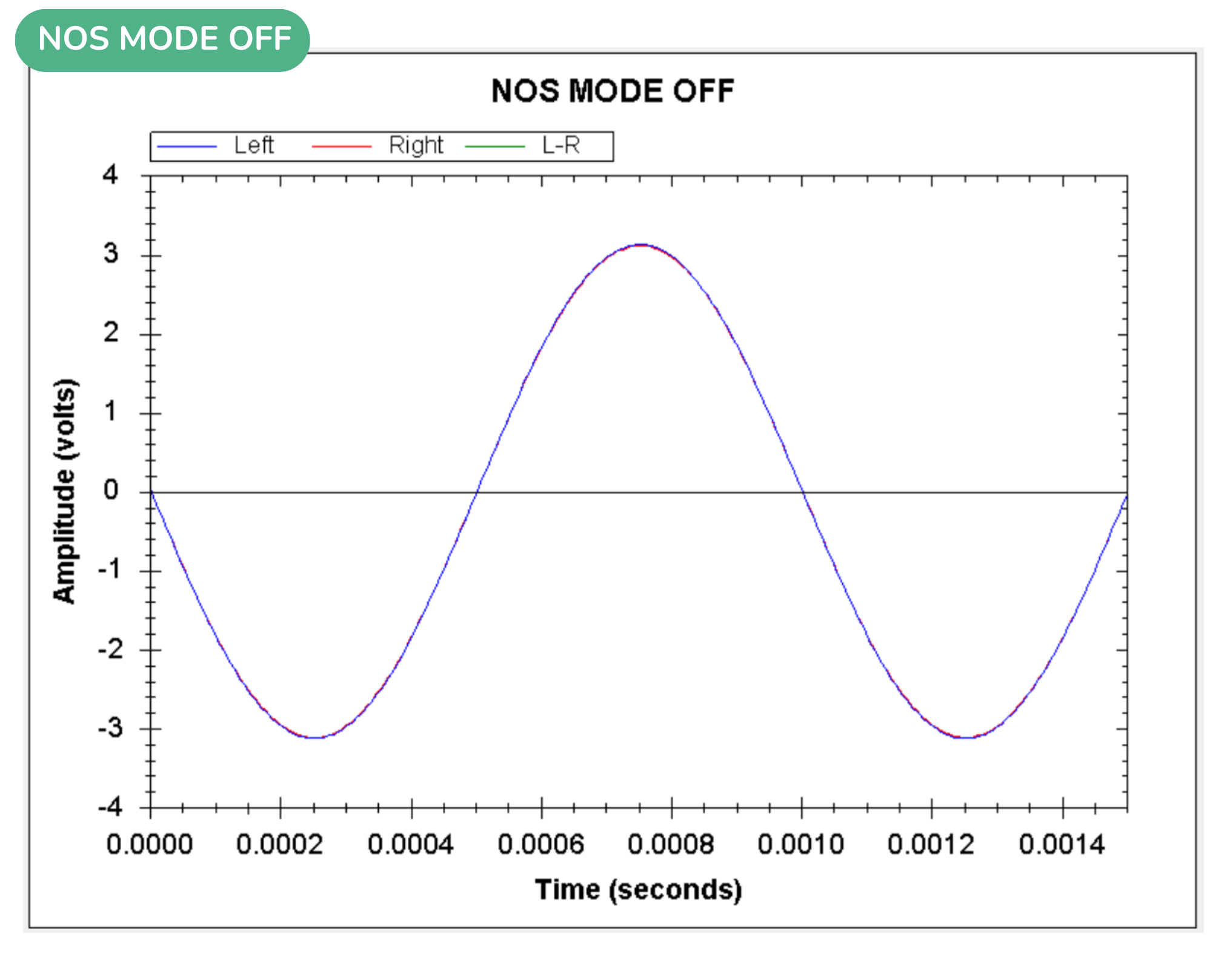
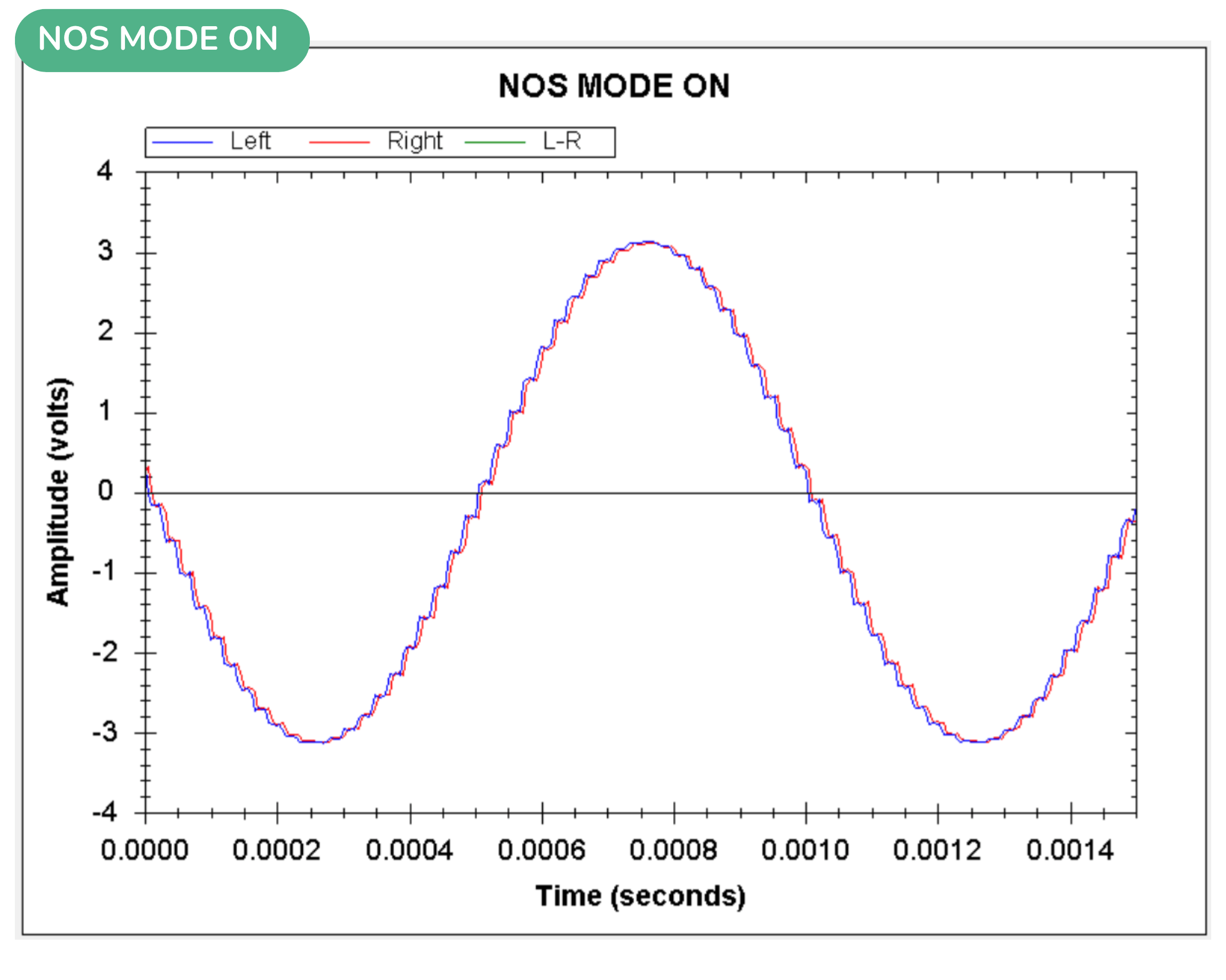
 Want to try it yourself? Learn more about Volumio Preciso and order yours
Want to try it yourself? Learn more about Volumio Preciso and order yours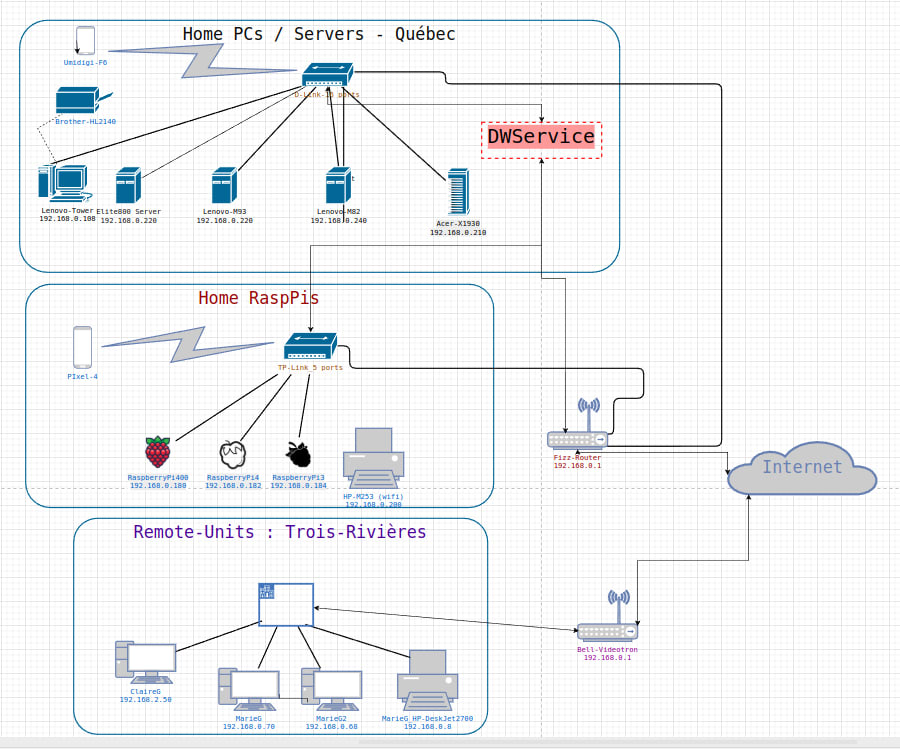 Marc’s LAN and WAN setup overview
Marc’s LAN and WAN setup overview Machines setup by Marc in his homelab
Machines setup by Marc in his homelab His Landscape setup
His Landscape setup The remote support utility : accessed via desktop or command-line (DWService)
The remote support utility : accessed via desktop or command-line (DWService)