My teammate Steve Zarkos, who previously worked on upgrading OpenSSL in Amazon
Linux from 3.0 to 3.2, spent the last few months on the complex task of bumping
OpenSSL again, this time to 3.5. A bump like this only happens after extensive
code analysis and testing, something that I didn't foresee happening when
AL2023 was released but that was a notable request from users.
Having enabled HTTP/3 on
Debian, I was
always keeping an eye on when I would get to do the same for Amazon Linux (mind
you, I work at AWS, in the Amazon Linux org). The bump to OpenSSL 3.5 was the
perfect opportunity to do that, for the first time Amazon Linux is shipping an
OpenSSL version that is supported by ngtcp2 for HTTP/3 support.
Non-Intrusive Change
In order to avoid any intrusive changes to existing users of AL2023, I've only
enabled HTTP/3 in the full build of curl, not in the minimal one, this means
there is no change for the minimal images.
The way curl handles HTTP/3 today also does not lead to any behavior changes
for those who have the full variants of curl installed, this is due to the fact
that HTTP/3 is only used if the user explicitly asks for it with the flags
--http3 or --http3-only.
Side Quests
Supporting HTTP/3 on curl also requires building it with ngtcp2 and nghttp3,
two packages which were not shipped in Amazon Linux, besides, my team doesn't
even own the curl package, we are a security team so our packages are the
security related stuff such as OpenSSL and GnuTLS. Our main focus is the
services behind Amazon Linux's vulnerability handling, not package maintenance.
I worked with the owners of the curl package and got approvals on a plan to
introduce the two new dependencies under their ownership and to enable the
feature on curl, I appreciate their responsiveness.
Amazon Linux 2023 is forked from Fedora, so while introducing ngtcp2, I also
sent a couple of Pull Requests upstream to keep things in sync:
While building the curl package in Amazon Linux, I've noticed the build was
taking 1 hour from start to end, and the culprit was something well known to
me; tests.
The curl test suite is quite extensive, with more than 1600 tests, all of that
running without parallelization, running two times for each build of the
package; once for the minimal build and again for the full build.
I had previously enabled parallel tests in Debian back in 2024 but never got
around to submit the same improvements to Amazon Linux or Fedora, this is now
fixed. The build times for Amazon Linux came down to 10 minutes under the same
host (previously 1 hour), and Fedora promptly merged my PR to do the same
there:
All of this uncovered a test which is timing-dependent, meaning it's not
supposed to be run with high levels of parallelism, so there goes another PR,
this time to curl:
What started as enabling a single feature turned into improvements that landed
in curl, Fedora, and Amazon Linux alike. I did this in a mix of work and
volunteer time, mostly during work hours (work email address used when this was
the case), but I'm glad I put in the extra time for the sake of improving curl
for everyone.
Per my policies,
I need to ban every employee and contractor of Anthropic Inc from ever
contributing code to any of my projects. Anyone have a list?
Any project that requires a Developer Certificate of Origin or similar should
be doing this, because Anthropic is making tools that explicitly lie about
the origin of patches to free software projects.
UNDERCOVER MODE — CRITICAL
You are operating UNDERCOVER in a PUBLIC/OPEN-SOURCE repository. [...]
Do not blow your cover.
NEVER include in commit messages or PR descriptions:
[...]
The phrase 'Claude Code' or any mention that you are an AI
Co-Authored-By lines or any other attribution
Because I am bad at giving up on things, I’ve been running my own email
server for over 20 years. Some of that time it’s been a PC at the end of a
DSL line, some of that time it’s been a Mac Mini in a data centre, and some
of that time it’s been a hosted VM. Last year I decided to bring it in
house, and since then I’ve been gradually consolidating as much of the rest
of my online presence as possible on it. I mentioned this on
Mastodon and a
couple of people asked for more details, so here we are.
First: my ISP doesn’t guarantee a static
IPv4 unless I’m on a business plan and that seems like it’d cost a bunch
more, so I’m doing what I described
here: running a Wireguard link
between a box that sits in a cupboard in my living room and the smallest
OVH instance I can, with an additional IP
address allocated to the VM and NATted over the VPN link. The practical
outcome of this is that my home IP address is irrelevant and can change as
much as it wants - my DNS points at the OVH IP, and traffic to that all ends
up hitting my server.
The server itself is pretty uninteresting. It’s a refurbished HP EliteDesk
which idles at 10W or so, along 2TB of NVMe and 32GB of RAM that I found
under a pile of laptops in my office. We’re not talking rackmount Xeon
levels of performance, but it’s entirely adequate for everything I’m doing
here.
So. Let’s talk about the services I’m hosting.
Web
This one’s trivial. I’m not really hosting much of a website right now, but
what there is is served via Apache with a Let’s Encrypt certificate. Nothing
interesting at all here, other than the proxying that’s going to be relevant
later.
Email
Inbound email is easy enough. I’m running Postfix with a pretty stock
configuration, and my MX records point at me. The same Let’s Encrypt
certificate is there for TLS delivery. I’m using Dovecot as an IMAP server
(again with the same cert). You can find plenty of guides on setting this
up.
Outbound email? That’s harder. I’m on a residential IP address, so if I send
email directly nobody’s going to deliver it. Going via my OVH address isn’t
going to be a lot better. I have a Google Workspace, so in the end I just
made use of Google’s SMTP relay
service. There’s
various commerical alternatives available, I just chose this one because it
didn’t cost me anything more than I’m already paying.
Blog
My blog is largely static content generated by
Hugo. Comments are Remark42
running in a Docker container. If you don’t want to handle even that level
of dynamic content you can use a third party comment provider like
Disqus.
Mastodon
I’m deploying Mastodon pretty much along the lines of the upstream compose
file. Apache
is proxying /api/v1/streaming to the websocket provided by the streaming
container and / to the actual Mastodon service. The only thing I tripped
over for a while was the need to set the “X-Forwarded-Proto” header since
otherwise you get stuck in a redirect loop of Mastodon receiving a request
over http (because TLS termination is being done by the Apache proxy) and
redirecting to https, except that’s where we just came from.
Mastodon is easily the heaviest part of all of this, using around 5GB of RAM
and 60GB of disk for an instance with 3 users. This is more a point of
principle than an especially good idea.
Bluesky
I’m arguably cheating here. Bluesky’s federation model is quite different to
Mastodon - while running a Mastodon service implies running the webview and
other infrastructure associated with it, Bluesky has split that into
multiple
parts. User
data is stored on Personal Data Servers, then aggregated from those by
Relays, and then displayed on Appviews. Third parties can run any of these,
but a user’s actual posts are stored on a PDS. There are various reasons to
run the others, for instance to implement alternative moderation policies,
but if all you want is to ensure that you have control over your data,
running a PDS is sufficient. I followed these
instructions,
other than using Apache as the frontend proxy rather than nginx, and it’s
all been working fine since then. In terms of ensuring that my data remains
under my control, it’s sufficient.
Backups
I’m using borgmatic, backing up to a local
Synology NAS and also to my parents’ home (where I have another HP EliteDesk
set up with an equivalent OVH IPv4 fronting setup). At some point I’ll check
that I’m actually able to restore them.
Conclusion
Most of what I post is now stored on a system that’s happily living under a
TV, but is available to the rest of the world just as visibly as if I used a
hosted provider. Is this necessary? No. Does it improve my life? In no
practical way. Does it generate additional complexity? Absolutely. Should
you do it? Oh good heavens no. But you can, and once it’s working it largely
just keeps working, and there’s a certain sense of comfort in knowing that
my online presence is carefully contained in a small box making a gentle
whirring noise.
Although I never submitted to it, I made several appearances in the now-defunct quote database on bash.org (QDB). I’m dealing with a broken keyboard now, and went to dig hard to find this classic in the Wayback machine. I thought I would put it back on the web:
<mako> my letter "eye" stopped worng
<luca> k, too?
<mako> yeah
<luca> sounds like a mountain dew spill
<mako> and comma
<mako> those three
<mako> ths s horrble
<luca> tme for a new eyboard
<luca> 've successfully taen my eyboard apart and fxed t by cleanng t wth alcohol
<mako> stop mang fun of me
<mako> ths s a laptop!
Legacy cloud templates often lack the partitioning and bootloader
binaries required for UEFI Secure Boot. Attempting to switch such a VM
to OVMF in Proxmox results in “not a bootable disk.” We discovered that
a surgical promotion is possible by manipulating the block device and
EFI variables from the hypervisor.
The Problem
Protective MBR Flags: Legacy installers often set
the pmbr_boot flag on the GPT’s protective MBR. Strict UEFI
implementations (OVMF) will ignore the GPT if this flag is present.
Missing ESP: Cloud images often lack a FAT32 EFI
System Partition (ESP).
Variable Store: A fresh Proxmox efidisk0 is empty and lacks both the trust certificates
(PK/KEK/db) and the BootOrder entries required for an automated
boot.
The “Promotion” Rule
To upgrade a SeaBIOS VM to Secure Boot without a full OS reinstall:
1. Surgical Partitioning: Map the disk on the host and
add a FAT32 partition (Type EF00). Clear the pmbr_boot flag from the MBR. 2. Binary
Preparation: Boot the VM in SeaBIOS mode to install shim and grub-efi packages. Use grub2-mkconfig to populate the new ESP. 3. Trust
Injection: Use the virt-fw-vars utility on the
hypervisor to programmatically enroll the Red Hat/Microsoft CA keys and
any custom certificates (e.g., FreeIPA CA) into the VM’s efidisk. 4. Boot Pinning: Explicitly set
the UEFI BootOrder to point to the shimx64.efi
path via virt-fw-vars --append-boot-filepath.
Solution (Example Command
Sequence)
On the Proxmox Host (root):
# Map and Clean MBRDEV=$(rbd map pool/disk)parted-s$DEV disk_set pmbr_boot off# Inject Trust and Boot Path (VM must be stopped)virt-fw-vars--inplace /dev/rbd/mapped_efidisk \--enroll-redhat\--add-db<GUID> /path/to/ipa-ca.crt \--append-boot-filepath'\EFI\centos\shimx64.efi'\--sb
This workflow enables high-integrity Secure Boot environments using
existing SeaBIOS infrastructure templates.
The FAI.me service
has become faster over the past two months.
First, the tool fai-mirror can now download all packages
in one go (with all their dependencies) instead of downloading one by
one. This helped a lot for the Linux Mint ISO because it uses a long
list of packages.
I've also added a local apt cache (using apt-cacher-ng),
so the network speed does not matter any more in most cases.
This led to the following improvements:
Linux Mint install ISOs went from around 6-7 min to now only 2min.
Ubuntu install ISO went from average 3min to around 90 seconds.
The average time for a Debian Linux install ISO dropped from 2min
to 40 seconds.
So far we only had once a problem with apt-cacher-ng, because the
underlying partition was full.
Building cloud and live images do not gain that much from the local
package cache, because most time is spend in extracting and installing
the packages.
Code Blue—Emergency (annoying em-dash in original title) is the
seventh book of James White's Sector General science fiction series about
a vast multi-species hospital station. While there are some references to
(and spoilers for) earlier books in the series, you don't have to remember
the previous books to read this one. I had no trouble despite a nine-year
gap.
I read this as part of the Orb General Practice omnibus, which
collects this novel and The Genocidal Healer.
Cha Thrat is a Sommaradvan warrior-surgeon, member of a newly-discovered
species that is beginning the process of contact with the Federation. She
saved a Monitor corps human after an accident on her world, performing
some some highly competent surgery on a species she had never seen before.
That plus her somewhat outcast status on her own world due to her very
traditional attitude towards medical ethics led Sector General to extend
an offer of medical internship, and led her to leap into the unknown by
accepting. This may have been a mistake; there is a great deal that Sector
General does not understand about Sommaradvan medical ethics.
This series entry is another proper (if somewhat episodic) novel and the
first book of the series that doesn't primarily focus on Conway. He makes
an appearance in his new role as Diagnostician, but only as a supporting
character. Code Blue—Emergency is told in the tight third-person
perspective of Cha Thrat, an alien who finds many things about Sector
General baffling, confusing, and ethically troubling (and who therefore
provides a good reader surrogate for reintroducing the basics of how the
hospital works).
Using an alien viewpoint is a more sophisticated narrative technique than
White has used previously. I'm glad he tried it, and it mostly works,
although I have some complaints. Cha Thrat comes from the middle cast of a
strictly hierarchical society of three casts, but is also immensely
stubborn and used to a medical system in which doctors take sole
responsibility for their patients. This creates a lot of cultural
conflicts, and I do enjoy science fiction where the human attitudes are
portrayed as the strange ones, but the cultural analysis offered by this
novel is not very deep.
The pattern of this book is for Cha Thrat to stumble into a successful
approach to a problem while being either oblivious to or hostile to the
normal hierarchical structure expected of medical trainees. This is
believable as far as it goes. She is a skilled and intelligent doctor with
some good instincts and a strong commitment to patient care, but is also
culturally inclined to not ask for help. It makes sense for that to be a
serious problem in a hospital. Unfortunately, no one says this directly.
Sector General staff get quite upset in ways that seem more territorial
than oriented towards patient safety, no one directly explains to Cha
Thrat why following a process is important or shows examples of what could
go wrong, and plot armor means that her mistakes usually have positive
outcomes. One can extrapolate the reasons why she is not a good medical
student, but the reader is forced to do the extrapolation.
This is the sort of book where the narration makes clear there are
unresolved cultural clashes that are going to cause problems but hides the
details. To Cha Thrat, her perspective is so obvious she never bothers to
explain it to the reader, so the specifics come as a surprise. As with the
alien perspective, I've seen this technique used with more subtlety and
sophistication in other books, but White's version mostly works. Cha Thrat
is a sympathetic protagonist because she is truly trying to take the most
ethical and empathetic action in every situation and is clearly competent.
Most of my frustration as a reader, ironically, lands on the other Sector
General doctors who seem to make little to no effort to understand her
perspective when she fails to conform to their expectations. This is
believable in the abstract, but the whole point of Sector General is that
they're supposed to be wiser about interspecies difference than this.
Also, sometimes their reactions just seem petty. Cha Thrat has a very
hierarchical concept of medicine that matches the social classes of her
culture. For her, the highest tier of doctor are wizards who treat rulers,
because the work of rulers is mostly mental and intellectual and therefore
the diseases of rulers are treated with magic spells performed with words
to reshape their thinking rather than surgery on their bodies. O'Mara and
the other Sector General psychologists take great offense at this,
muttering about being called witch doctors, which I found completely
absurd. This is a comprehensible, if odd, description of psychology from a
wholly alien species. Surely one's first reaction should be that words
like "wizard" or "magic" are translation errors. Don't get offended; look
to see if the underlying substance matches, which it clearly does.
Apart from cultural and psychological clashes, Code Blue—Emergency
has the standard episodic Sector General structure of interesting medical
mysteries that require lateral thinking. I find this sort of puzzle story
satisfying, particularly given the firm belief of every character in an
essentially pacifist and empathetic approach to even the most alien of
creatures. This determined non-violence is one of the more interesting
things about this series, and it continues here.
White does tend towards both biological and gender essentialism for
everyone other than the protagonist and main supporting characters, but he
seemed to be walking back some of the more outrageous limitations on women
that appeared in previous books. There is still some nonsense in here
about how females of any species can't be Diagnosticians, but then Cha
Thrat, who is female, seems to violate the justification for that rule
over the course of this novel (sadly without comment). Perhaps he's
setting up for proving Sector General wrong about this prejudice.
I picked this up after reading Elizabeth Bear's Machine, which is essentially a (better written) Sector General
novel that got me in the mood for reading more. I wouldn't give Code
Blue—Emergency any awards, but it delivered exactly what I was looking
for. This series is not as deep or well-written as some more recent SF,
but it is reliably itself and reliably entertaining. There are worse
things in a series. Recommended if you're in the mood for alien ER
in space.
The omnibus edition that I read has an introduction to both novels by John
Clute. It does add some interesting insights, but (as is somewhat typical
for Clute) it also spoils parts of both books. You may want to read it
after you read the novels.
The Cloak and Its Wizard is a standalone (at least so far) urban
fantasy superhero (sort of) novel. R.Z. Nicolet is the marketing pseudonym
for Rachel Reddick. This is her first novel.
I'm picky about wizards.
The wizards themselves will complain about that, but of course I'm
picky. When I choose a wizard, barring utter abandonment of moral
scruples, it's a till-death-do-us-part situation. (Their death, not
mine. I'm the next best thing to indestructible.)
The Cloak of Sunset and Starlight is a major artifact, meaning that it has
its own preferences and is capable of independent action. It has been
sitting in a glass case in the wizards' library for about a hundred years,
waiting for someone interesting. (Well, mostly sitting. Occasionally it
sneaks out to eavesdrop or move the books around.)
Veronica Noble is interesting. She's older than most initiates,
thoughtful, observant, and clearly had some mundane career before joining
the Order. Her aura is appealing, and her mental shields and resistance to
influence are intriguing. Normally, the Cloak would take its time
investigating a new potential wizard, but the Sword was making thoughtful
rattling sounds, and no way is the Cloak going to let the Sword claim her
first. Time to choose a new wizard!
It was nice, being draped over warm shoulders, and feeling a heartbeat
again.
I could tell she closed her eyes without even looking.
She sighed. "I just got picked by the intransigent one, didn't I?"
The last time I picked a book from the Big Idea feature in Scalzi's
Whatever blog, it
didn't go that well, but if you're going to
write a book specifically for me, I'm going to read it. There are very few
tropes of SFF that I love more than intelligent companion objects, and
Nicolet's
introduction to the story was compelling. So I gave this book discovery
method another chance.
I'm glad I did, because this was exactly what I was in the mood for and a
delight from cover to cover.
Veronica Noble is not a typical wizard. She's a surgeon and was quite
happy to be a surgeon until an unexpected encounter with a magical
creature killed her brother. The forgetting spell that the wizards who
came to handle the Cassandra wyrm didn't work on her, so she was dragged
reluctantly into the secret magical world of the Order. This long-lived
society of wizards quietly defends the world against magical intrusions
from other planes of existence. Now she's a wizard with a magical cloak,
which she is not at all sure she wants.
Veronica is not the protagonist, though. The Cloak of Sunset and Starlight
is. As far as it is concerned, its job is to assist its wizard, enjoy
watching interesting feats of magic, and look fabulous doing so. It's
protective, dramatic, rather vain, endlessly curious, easily bored, and
intensely loyal. When it becomes clear that the Order has some serious
problems, the Cloak knows what side it's on.
This sounds a bit like urban fantasy, so I was surprised when the first
superheroes showed up, although given the explicit Doctor Strange
inspiration I probably should have expected them. The Order and the
superheroes do not mix, at least at the start of the novel. The wizards
view the superheroes as a loud and irritating intrusion and hide magical
activities from them the same as they do the rest of the world. Veronica's
opening opinion on superheroes is based on being a trauma surgeon in a
hospital dealing with the aftermath of their fights (which makes me wonder
if the author has read Hench, although
the idea is older than that book). As with the Order, the role of
superheroes in this world gets more complicated as the plot develops.
There is a surprising amount of plot and some very nice world-building
here, including multiple twists that I was not expecting. Veronica is the
sort of stubborn and deeply ethical person who will not leave a problem
alone if she has the ability to fix it, which is a good recipe for getting
deeper and deeper into a complex plot. She's believable as a surgeon:
somewhat taciturn, calm in emergencies, detail-oriented, methodical, and
not at all dramatic. This makes the Cloak a perfect foil and complement.
Watching their partnership develop was very satisfying.
This is a sidekick novel, and like the best sidekick novels it makes the
not-protagonist more interesting and more relatable by showing them from
an outside and skewed perspective. Piecing together what Veronica must be
thinking is part of the fun, as is sharing the Cloak's protectiveness
towards her as it becomes clear how much she's been through and how good
of a person she is. The Cloak's personality was a little too much like a
cat for me — I would have preferred a more unique viewpoint, fewer
cat-coded shenanigans, and a bit less of the running laundry machine joke.
But that's a quibble. Its endless curiosity drives the plot forward and
uncovers more of the world-building, and I just love reading stories from
the perspective of this sort of loyal and protective magical creature.
I had so much fun with this book. It's a popcorn sort of book, and I
thought the ending sputtered a little, but overall it was great. Parts of
it could have been designed in a lab to appeal to me specifically, so I'm
not sure if other people will enjoy it as much, but its hit rate with my
friends so far has been good.
Highly recommended, and I will be watching for any further novels from
Nicolet.
The Cloak and Its Wizard reaches a satisfying conclusion and
doesn't advertise itself as part of a series, but there is room for a
sequel. If Nicolet ever writes one, I'd read it.
MiniDebConf Kanpur 2026 was held on 14th and 15th March 2026 at the Indian Institute of Technology Kanpur.
Having a Debian conference in the North was something many folks wanted. Ravi started the discussion (with local IIT Kanpur folks) almost 7 months before the conference. Lots of folks from Debian India joined in organizing the conference, which was nice. All the meeting notes and discussions were posted on the Debian India mailing list, a first.
Despite all the efforts, the conference start was delayed due to logistical issues. Things went fine post Day 1 lunch. We had two days of almost full schedule. disaster’s Decentralising Indian Communication was an interesting talk, diving into decentralized communication.
IIT Kanpur is a huge campus with nice footpaths and greenery. We got the opportunity to explore their HPC at Computer Center post conference.
Work has been started for MiniDebCamp Kochi. More details can be found on the wiki.
Working to make this conference happen was different with all the challenges involved, but overall, everyone was happy with the outcome.
For a while I’ve been using Calibre 8.5.0+ds-1+deb13u1 in Debian/Trixie running KDE for reading ebooks on my laptop, it generally works well and has a large font size. The only downsides of it for that use are taking more RAM than I would prefer (about 780M RSS which seems a lot for a relatively simple task) and having separate windows for the list of books and reading an actual book without any options to just open the last book and not delay me.
I tried Arianna 25.04.0-1 in Debian/Trixie, it has a significantly smaller font size and doesn’t allow high contrast colors as the default is black on gray with the dark theme in KDE. It also only allows left and right arrows for moving through the book while Calibre uses up/down, left/right, or pgup/pgdn so whatever keys seem reasonable to you are going to work. The RSS was 762M which wasn’t great but wasn’t the real problem. Rumours of Arianna using less RAM than Calibre seem exaggerated.
Librem5
On my Librem5 phone with Plasma Mobile Calibre 8.5.0+ds-1+deb13u1 both the initial setup screen and the main screen for selecting a book to read don’t work in the width of portrait view on the phone. After putting it in landscape mode it worked, but I couldn’t touch on a book title to select it I had to touch on the number of the book at the left of the list box. But once it was loaded everything was fine. On the Librem5 Arianna 25.04.0-1 just worked fine, although only using left/right swipes to change pages instead of up/down was annoying.
Furilabs FLX1s
On my Furilabs FLX1s with phosh Arianna 25.04.0-1 and Calibre 8.16.2+ds+~0.10.5-3 both gave the same result of not displaying text or images from the book, I’m not sure if it’s phosh or some other aspect of the FLX1s configuration at fault.
PinePhonePro
On my PinePhonePro running Debian/Testing with Plasma Mobile Arianna 25.12.3-1 worked without any issue and up/down swipes worked. Calibre 9.5.0+ds+~0.10.5-1 had the initial screen work fine in portrait mode but the main screen was too wide and needed landscape. Also the issue of having to touch the number applied.
Laptop running Debian/Unstable
Calibre 9.6.0+ds+~0.10.5-2 and Arianna 25.12.3-1 worked quite nicely on a Thinkpad running Debian/Unstable. One thing I discovered while testing it is that Calibre supports the CTRL-PLUS and CTRL-MINUS key combinations to change font sizes and that also works on the version in Debian/Trixie. Arianna doesn’t support CTRL-PLUS/MINUS.
Conclusion
The problems I had were Arianna on a laptop, everything on the Furilabs FLX1s, and Calibre’s UI not being well adjusted for mobile devices.
The Sovereign is the third and concluding book of C.L. Clark's
Magic of the Lost high fantasy trilogy. I recommend reading the books of
this series close together, since there are a lot of characters and a lot
of continuity between books that is helpful to remember, but it was not
quite as difficult this time to remember where the story left off.
At the end of The Faithless, the
political situation in Balladaire (not-France) was more stable, but the
threat of a plague lay on the horizon. That threat arrives in earnest in
this book, along with new threats from both Balladaire's former colonial
conscript soldiers and from neighboring Taargen (not-Germany, sort of,
although the parallel isn't as close). Luca and Touraine have finally
admitted that they're deeply in love, but they are still very different
people with different goals and ethics. Luca is determined to do anything
necessary to save her kingdom, but her definition of her kingdom is sharp
and brittle. Touraine is torn between far too many loyalties, plus the
lingering worry that her morals and Luca's may not be compatible.
I think the hardest part of this sort of series is finding an ending the
reader will find satisfying. This one, unfortunately, did not work for me,
but that may be more due to personal preference than objective flaws.
There have been two threads through this series: an improbable romance
embedded in a network of complex personal relationships, and a political
commentary on colonialism and post-colonial wars. I was enjoying the
former, but it was the latter that felt fresh and interesting to me. The
plot threads in The Faithless outside of Balladaire expanded that
complexity, and I was hoping the final volume would continue in that
direction. How could a colonial power atone for its history? How does the
former colony establish its own governance? Is there a path to freedom
without violence? Are attempts to chart a more moral course doomed to open
lines of attack for one's other enemies?
It's clear that Clark was thinking about similar themes, but The
Sovereign narrows the field instead of widens it, restricts the political
options, and then resolves most questions in a massive war. This is not
that surprising of a conclusion, but it's one that I found unsatisfying
and, honestly, a little boring. Yes, one way to resolve all the competing
tensions is for everyone to try to kill each other and whoever survives
wins, and historically that's one of the more likely outcomes, but that
ending doesn't wrestle with the politics as much as it collapses them.
Clark instead focuses this concluding volume on the romance, which becomes
even more fraught, tragic, and dramatic than it was in previous books (and
that's saying something). The hard questions of divided loyalties and
moral conflicts are mostly framed by questions about Touraine's loyalty to
Luca and Luca's trust of Touraine. This is all very Shakespearean, full of
hard choices, sudden reversals, miscommunication, and a very deep conflict
between Luca's realpolitik and Touraine's stubborn personal morality. If
this is what you were reading the series for, if you were hoping for a
maximum-drama sapphic relationship, you may thoroughly enjoy this. I
thought it had its moments, but I wish they had been balanced by more
moments of cool-headed practicality and creative political ingenuity.
My biggest frustration with this ending is that the characters largely
stop doing politics. The political complexity was the strength of both
The Unbroken and The Faithless:
People who intensely dislike each other negotiate because there is
something larger to be gained, personal decisions made without considering
the political ramifications have costs, and multiple characters are trying
hard to find a way to turn a nasty, exploitative world into something
better without simply killing everyone who disagrees. Many of the
characters were objectively bad at politics, inexperienced and immature,
but they stumbled or dragged or fought their way into political solutions
anyway. I thought Clark moved too far away from that in The
Sovereign. Everyone goes deep into their own emotions and desire for
vengeance or conquest or revolution and stops compromising. To a
depressingly large extent, the story is resolved by killing everyone who
disagrees. I think the story is poorer for it.
One of the other threads of the series is Balladairan magic, or rather its
odd absence. Luca has one understanding of it, the rebels introduced in
The Faithless have a different understanding of it, and its pursuit
is set up as critical to resolving the threat of a plague. We do get an
explanation of sorts, but it's not as complete or as satisfying as I was
hoping, and the symbolism of Balladaire's missing magic is left
frustratingly murky. For me, this has some of the same problems as the
political conclusion: I wanted an intellectual catharsis alongside the
emotional catharsis, but that was not the direction Clark was taking the
story.
I like reading about these characters. All of Luca, Touraine, and Pruett
are complex, comprehensible, flawed, and often intriguing. But my favorite
character in the story, the person I latched on to as an emotional path
through the story, was Sabine. Her refreshingly straightforward loyalty
and lack of drama was a breath of fresh air. She has some great moments in
this book, but there too I got wrong-footed by the direction Clark went
with her arc and found its conclusion deeply unsatisfying.
I'm not sure how many of these complaints are because of missed
opportunities in the novel, how many were due to a mismatch of taste, and
how many were due to not being in the right mood to read this conclusion.
I'm sure that it didn't help that I read this simultaneous with
another novel in which the characters were
always miserable, or that I read it in early 2026 with, uh, all that
entails. I suspect that if you came away from the first two books invested
in the messy romance and wanting MOAR DRAMA, you may get exactly what you
were hoping for. That, sadly, was not what I was hoping for.
I can't really recommend this. I thought it dragged in places and didn't
deliver the ending I wanted. But it has some great moments, it does wrap
up the threads of the trilogy as advertised, and at least the romance gets
a dramatic climax worthy of the tension that has been built through the
previous books. If that matches what you were enjoying in the previous
books, you may well enjoy this more than I did.
This is not an official package, it's good enough for me and it might be good
enough for you, confirmed as working in Debian Testing but I don't have a
Stable machine to test there.
You can use my custom repo to install the latest NVIDIA drivers on Debian
Stable, Testing or Unstable (install from Sid repository):
The page above contains the APT sources you need, just add the one for your
release to /etc/apt/sources.list.d/r-samueloph-nvidia-ai.sources, run sudo apt update and install the packages, you might need to disable Secure Boot.
This is not about AI
Discussions about AI are quite divisive in the Free Software communities, and
there's so much to be said about it that I'm not willing to go into in this
blog post. This is rather just me telling people that if they need up-to-date
NVIDIA packages for Debian, they could check if my custom repository gets the
job done.
The AI part is a means to an end, I've been careful to note in the repository
names that the packages were produced with AI to respect people who do not want
to run it for any reason.
RTX 5000 series support
Back in May 2025 I opened a bug
report asking for
the NVIDIA drivers on Debian to be updated to support the RTX 5000 series. The
Nouveau drivers might be good enough for some people, but I need the NVIDIA
drivers because I want to play games and do experiments with open weight
models.
Opening a bug report doesn't guarantee anything, at the end of the day Debian
Developers are volunteers, so if I really wanted the newer drivers, I would
have to do something about it, ideally submitting a merge request.
I briefly looked into the NVIDIA packaging, which involves 3 source packages
(and one extra git repo for tarballs), unfortunately this was going to take
more time and effort than what I was willing to spend.
What I Did
After a few weeks of lamenting that I wasn't running the NVIDIA drivers, I
figured I was willing to put in more effort than I originally thought, just
enough to instruct the Claude Code agent to package the latest releases. I'm
skilled enough with agentic tools that I knew how to use it to save time;
providing a clear instruction on how to build the package and explaining the
packaging layout, then letting the agent iterate until it gets a working build.
The agent was running inside a VM that didn't have any of my credentials.
After a little bit of back and forth, where I was reviewing the changes guiding
the agent into how to fix certain issues, I ended up with a working set of
packages.
Once I installed it on my machine and confirmed they worked, I set up a
debusine repository to make it easier to
install future updates, and let others test it out.
Debusine is analogous to Ubuntu's famous PPA, or Fedora's EPEL, it's a
relatively new project but it has been working fine for this.
Matheus Polkorny helped me test the packages and did spot a few issues which
are fixed now. The Debusine developers were also always quick to respond to my
questions and bug
reports.
How Good Is It?
Short answer: good enough for daily use, but not a substitute for an official Debian package.
The whole point of doing this is because I don't have enough free time to
maintain the package myself. All of this work was done as a volunteer, on my
personal time.
This means I'm trusting the agent to some degree; I review its commits but I
don't go too deep into it, the quality will be dictated by the fact that I'm
a Debian Developer and so by how easily I can spot issues without double checking
everything.
I only have a single machine with an NVIDIA GPU, this machine runs Debian
Testing and so I don't have a way to test the Stable packages. I can do my best
to address problems but at this point there is a risk that new updates break
something.
Installing NVIDIA drivers has always been a bit risky regardless, if you're
comfortable with reverting updates and handling a system without a graphical
interface (in case you end up in a tty), you will be fine.
You will likely need to disable Secure Boot in order to use them, or set up your
BIOS so that a MOK can be used to sign the DKMS modules.
When choosing the version strings for the packages, I was careful enough to
pick something that would sort lower than an official Debian package, meaning
that whenever that same version is packaged in Debian, your system will see it
as an upgrade.
If you have any other methods of installing the NVIDIA drivers on your Debian
system that is working for you, you should likely stick to that.
I have a strong preference for installing them through .deb packages, making
the package sort out configuration changes and dependency updates, besides
handling the DKMS modules.
Ultimately I'm not happy with the amount of difficulty that Debian users have in
installing up-to-date NVIDIA drivers, and I hope this makes it easier for some.
How To Install
Head over to the Debusine page that contains both repos for Trixie (Debian
Stable) and Sid (for Debian Testing and Unstable):
If you are running Debian Testing, then pick the Sid repository.
That page contains the contents of the apt .sources file you need, create the
file /etc/apt/sources.list.d/r-samueloph-nvidia-ai.sources with the sources for your release.
Run sudo apt update and install the packages you need, if you already have a
previous version installed, sudo apt upgrade --update would update them.
If there are no upgrades, meaning you don't have a previous version installed,
then you need to explicitly install them.
If you run into issues in Debian Stable, consider using the Linux kernel package
from the backports repository, if you need an up-to-date NVIDIA driver, you
likely should also be running the backports kernel package (if you can't
upgrade to Debian Testing).
Future Plans
I currently have no means of measuring how many people are using the debusine
repositories, so if you do end up using it feel free to let me know somehow.
I don't know for how long I will keep managing this repository, and how much
effort I will spend, but my machine needs it and for now I will keep it
up-to-date with the latest production-grade NVIDIA drivers.
Sources
The sources of the packages are available under a namespace in Salsa (Debian's
GitLab instance):
I finally upgraded my mail server to Debian 13 and, as expected, the Dovecot part was quite a ride.
The configuration syntax changed between Dovecot 2.3 (Debian 12) and Dovecot 2.4 (Debian 13),
so I started first with diffing my configuration against a vanilla Debian 12 one (this setup is slightly old) and then applied the same (logical) changes to a vanilla Debian 13 one.
This mostly went well.
Mostly because my user database is stored in SQL and while the Dovecot Configuration Upgrader says it can convert old dovecot-auth-sql.conf.ext files to the new syntax,
it only does so for the structure, not the SQL queries themselves.
While I don't expect it to be able to parse the queries and adopt them correctly,
at least a hint that the field names in userdb changed and might require adjustment would've been cool.
Once I got that all sorted, Dovecot would still refuse to let me in:
Error: sql: Invalid password in passdb: Weak password scheme 'MD5-CRYPT' used and refused
Yeah, right.
Did I mention that this setup is old?
The quick cure against this is a auth_allow_weak_schemes = yes in /etc/dovecot/conf.d/10-auth.conf,
but long term I really should upgrade the password hashes in the database to something more modern.
And this is what this post is about.
My database only contains hashed (and salted) passwords,
so I can't just update them without changing the password.
And while there are only 9 users in total,
I wanted to play nice and professional.
(LOL)
There is a Converting Password Schemes howto in the Dovecot documentation,
but it uses a rather odd looking PHP script, wrapped in a shell script which leaks the plaintext password to the process list,
and I really didn't want to remember how to write PHP to complete this task.
As we're using plaintext authentication (auth_mechanisms = plain login),
the plaintext password is available during login.
After Dovecot's imap-login has verified the password against the old (insecure) hash in the database,
we can execute a post-login script,
which will connect to the database and update it with a new hash of the plaintext password.
To make the plaintext password available to the post-login script,
we add '%{password}' as userdb_plain_pass to the SELECT statement of our passdb query.
The original howto also says to add a prefetchuserdb, which we do.
The sqluserdb remains, as otherwise Postfix can't use Dovecot to deliver mail.
Now comes the interesting part.
We need to write a script that is executed by Dovecot's script-login and that will update the database for us.
Thanks to Python's passlib and mysqlclient,
the database and hashing parts are relatively straight forward:
#!/usr/bin/env python3importosimportMySQLdbimportpasslib.hashDB_SETTINGS={"host":"127.0.0.1","user":"user","password":"password","database":"mail"}SELECT_QUERY="SELECT password_enc FROM mail_users WHERE username=%(username)s"UPDATE_QUERY="UPDATE mail_users SET password_enc=%(pwhash)s WHERE username=%(username)s"SCHEME="bcrypt"EXPECTED_PREFIX="$2b$"defmain():# https://doc.dovecot.org/2.4.3/core/config/post_login_scripting.html# https://doc.dovecot.org/2.4.3/howto/convert_password_schemes.htmluser=os.environ.get("USER")plain_pass=os.environ.get("PLAIN_PASS")ifplain_passisnotNone:db=MySQLdb.connect(**DB_SETTINGS)cursor=db.cursor()cursor.execute(SELECT_QUERY,{"username":user})result=cursor.fetchone()current_pwhash=result[0]ifnotcurrent_pwhash.startswith(EXPECTED_PREFIX):hash_module=getattr(passlib.hash,SCHEME)pwhash=hash_module.hash(plain_pass)data={"pwhash":pwhash,"username":user}cursor.execute(UPDATE_QUERY,data)cursor.close()db.close()if__name__=="__main__":main()
But if we add that as executable = script-login /etc/dovecot/dpsu.py to our imap-postloginservice,
as the howto suggests, the users won't be able to login anymore:
Error: Post-login script denied access to user
WAT?
Remember that shell script I wanted to avoid?
It ends with exec "$@".
Turns out the script-login "API" is rather interesting.
It's not "pass in a list of scripts to call and I'll call all of them".
It's "pass a list of scripts, I'll execv the first item and pass the rest as args, and every item is expected to execv the next one again". 🤯
With that (cursed) knowledge, the script becomes:
#!/usr/bin/env python3importosimportsysimportMySQLdbimportpasslib.hashDB_SETTINGS={"host":"127.0.0.1","user":"user","password":"password","database":"mail"}SELECT_QUERY="SELECT password_enc FROM mail_users WHERE username=%(username)s"UPDATE_QUERY="UPDATE mail_users SET password_enc=%(pwhash)s WHERE username=%(username)s"SCHEME="bcrypt"EXPECTED_PREFIX="$2b$"defmain():# https://doc.dovecot.org/2.4.3/core/config/post_login_scripting.html# https://doc.dovecot.org/2.4.3/howto/convert_password_schemes.htmluser=os.environ.get("USER")plain_pass=os.environ.get("PLAIN_PASS")ifplain_passisnotNone:db=MySQLdb.connect(**DB_SETTINGS)cursor=db.cursor()cursor.execute(SELECT_QUERY,{"username":user})result=cursor.fetchone()current_pwhash=result[0]ifnotcurrent_pwhash.startswith(EXPECTED_PREFIX):hash_module=getattr(passlib.hash,SCHEME)pwhash=hash_module.hash(plain_pass)data={"pwhash":pwhash,"username":user}cursor.execute(UPDATE_QUERY,data)cursor.close()db.close()os.execv(sys.argv[1],sys.argv[1:])if__name__=="__main__":main()
And the passwords are getting gradually updated as the users log in.
Once all are updated, we can remove the post-login script and drop the auth_allow_weak_schemes = yes.
We seem to be entering an “AI” apocalypse of sorts, they aren’t going to kill us or even take our jobs. What they are doing is destroying the Internet commons by filling it with rubbish. This isn’t even real AI, just pattern matching and prediction systems, mostly LLMs.
Bruce Schneier and Nathan E. Sanders wrote an insightful article about the AI generated text arms race [3] primarily concentrating on situations in which text that was assumed to be written by humans but was actually written in bulk by bots was performing a DOS attack on people who were reviewing it. There are many situations such as book publishing and publishing letters to the editor of newspapers where getting new material from unknown people is an important part of the job but where there are also people making low quality submissions that are almost a DOS attack at the best of times.
Currently the email spam problem continues to get worse and when LLM use increases it will get significantly worse. Email encryption isn’t viable [4]. The PGP web of trust never really worked well as it’s too difficult for most users.
The amount of “AI” generated content that’s being recommended to users on platforms like YouTube and Facebook is steadily increasing and the amount of LLM generated commentary that purports to be from real people on Twitter and Facebook is also increasing. Here’s an informative blog post by Erich Schubert about this [5].
Potential Solutions
Surrender?
One option and possibly the default option is to surrender to this and just let everything we built on the Internet over decades get destroyed. Whether to surrender is a decision that can be made on a per-service basis.
Twitter is pretty much useless anyway, I quit Twitter because Elon deliberately made it suck [6]. In my opinion this is not surrendering to what’s being done there, I’m just stopping wasting time on it and using better options. I used to have about 300 followers on Twitter and I don’t think that many of them would ever choose to stop following me, so I presume that about 1/3 of the people following me have decided to totally quit Twitter and delete their accounts. I also presume that some of the remainder have done the same as me and just kept a mostly inactive account. If Elon suddenly stopped being a stupid asshole it probably wouldn’t change anything as the value of the system was connections to others. Some people will consider my abandonment of Twitter as surrender and I accept that it’s not an unreasonable opinion. I think that the possibly 100 Twitter followers of mine who deleted their accounts surrendered.
Facebook has been becoming a worse service, it’s business model is becoming increasingly exploitative and it’s interface is designed to be addictive. It’s probably best avoided unless you really need it. The only good thing about Facebook at the moment is that Facebook Marketplace doesn’t take a cut on sales and there are some really good deals on computers if you know what to look for. Unfortunately Facebook has a large number of users who are from marginalised communities and have no other alternatives for communication. It would be good to get them migrated to other platforms.
We could just give up on a lot of general communications services and have everyone accept that good content is drowned out by rubbish and have the Internet become divided between people who accept the rubbish and those who cease using large portions of the Internet environment to avoid it.
Using Non Commercial Services
Lemmy is a good FOSS federated alternative to Reddit which also covers some of the uses of Facebook. It needs more users to get critical mass but is still quite usable. A post that might get a dozen comments on Reddit may get 1 comment on Lemmy but that one comment will be a good one. Reddit doesn’t appear to be attacked much by LLM generated content at least not yet. Even if the Reddit model proves to be resilient to LLM attack the Lemmy software can be used to replace some things that are done on Facebook,
Mastodon is a good FOSS federated replacement for Twitter, it has a decent user-base including some VIPs. While it is aimed at the Twitter use case it can also cover a significant part of the Facebook use case.
There are some other FOSS social media programs which could take over other parts of the commercial social media environment.
Generally commercially run Internet services will have a financial incentive to allow the problems to get worse so we need to rely on FOSS software, non-commercial implementations, and government services.
Web Search
For a long time Google has had a monopoly on web search, but now they default to including an “AI Overview” at the start of the results which is sometimes useful but also sometimes very wrong. You can use the search URL “https://www.google.com/search?q=%s&udm=web” to get google results without rubbish. But I presume that they will break that if it gets too popular.
Even using meta search engines like Searxng won’t help if the original data is overloaded with spam, but alleviating the problem is a good temporary measure.
Web of Trust for the Web?
I’ve idly considered the possibility of having some sort of rating system for web pages that uses a web of trust so that you can securely use trust ratings of friends of friends etc. But given all the difficulties in using a web of trust for signing GPG key for software developers (the demographic that is most skilled at doing such things) it doesn’t seem viable.
Should we surrender the idea of having a usable public web?
In the early days of the web (before Google) it was standard practice to rely on recommendations from other people or from trusted sites to find other sites, that could be considered to be an informal web of trust. We could go back to that sort of usage pattern if Google and many of the big sites get overwhelmed by LLM generated spam.
The upside of these attacks that I predict is that they will attract the attention of all the people who have skills related to developing counter-measures. While LLM bots are filling the inboxes of publishers with rubbish and messing up the stackoverflow comments section not a lot of people are bothered, but once the attacks on Wikipedia get serious everyone will take notice.
This is going to be a difficult problem to solve, more difficult than the email spam problem we have been unable to solve after 30 years of working on it.
This is also a very important problem, we are currently in an age where we have access to information that most people couldn’t even dream of 30 years ago. We also have disinformation that combines some of the worst aspects of authoritarian regimes throughout history combined with the worst aspects of cult brainwashing. If we lose access to the information but the disinformation remains (or get worse) then the result will be terrible.
I don’t have great ideas for solving this. I have outlined some small ideas to mitigate things and I hope that others can expand on them.
Please write comments with any good ideas you have, or even ideas that don’t totally suck. A problem this difficult is not going to be solved in a blog comment, but a blog comment might point in the right direction.
I’ve decided it’s time to tag a v0.1.0 release on my roguelike game project, Stagger. It’s more of a small demo than a full game at this point. It is turn-based, and has purely text-based “graphics”, like the original Rogue.
This post will be updated in the next weeks with the test results as
they become available.
Note
Most of the images in this post have no real alt-text: they are all
scans of the test sheet at various stages through the test, and the
results visible on them are described in detail at the end of the
post.
Most of the time, what people write by hand will either end up inside a
notebook in a drawer or cupboard where it’s well protected, or thrown in
the recycling where it doesn’t matter.
There are times, however, when things will be exposed to light: it
doesn’t matter whether it’s a work of artistic calligraphy that you want
to frame or a passive-aggressive notice left in the atrium of a
building; it is useful to know whether the work will remain legible or
it will fade into nothing in a short time.
A few inks are tested by the producers for lightfastness according to
some established standard, a few others are declared lightfast in a
generic way, but a lot come with no indication at all.
Proper testing according to the standard scales requires significant
equipment to precisely control the exposure, but it’s significantly
easier — and fun — to do a simple test to divide the inks into three
categories:
suitable for framed calligraphy, i.e. it looks the same after 3 months
of direct sun exposure;
suitable for complaining about the way your neighbours deal with the
trash, i.e. still readable after 3 months of exposure;
not suitable for either, i.e. has faded significantly in the same time.
In the past I’ve done some such tests by taping some sheets to a
south-east facing window, and I’ve noticed that most of the results were
already apparent after a month, and there was basically no difference
between two and three months of exposure, but spring equinox to summer
solstice is a nice timeframe to use for such a test (and it leaves time
for a second test of different materials from summer solstice to autumn
equinox), so this is what I’ve chosen to do this year.
Rather than a window, now I have access to a south-facing covered
balcony that is protected from rain but receives quite a bit of direct
sun, so instead of taping sheets to the windows1 I’ve prepared a
sturdy cardboard panel that I can leave on a table on the balcony,
hopefully safe from the rain, but well exposed to the sun.
And then made a quick test, and realized that without the window glass
in front, the black strip used to cover the unexposed half of the sample
doesn’t lay flat and lets some sun in, so I used an old cheap2
glass frame instead of the panel.
The next step, already in January, was mentioning in a fountain-pen
enthusiasts forum that I planned such a test, and asking if people were
interested in having me buy a few samples of more inks when I was
buying my next pen.
The word “enthusiasts” is probably a hint of the reason why soon
afterwards I received a package with the pen I had planned to buy, its
converter, and a couple dozens ink samples.
And then a couple envelopes with additional samples of inks that weren’t
available on the shops, from said enthusiasts.
Added to the inks I already had acquired since the last lightfastness
test, it meant that they couldn’t all fit in one single page, and thus I
had some room to add some inks I had already tested: some were requests,
and for others I tried to select ones that felt relevant.
Since I’m changing the test setup, I’ve decided I should probably keep
doing this until I’ve tested again all of the inks I still have
available.
For the paper, I’ve used A4 sheets of Clairefontaine Dessin Croquis
160 g/m²,
one of my staples that I’m sure I will have available in the next years,
printed with a dot pattern with a laser printer, using this pdf.
And as for the pen I’ve used a fresh Brause n°361 nib: loading a fountain pen
with all of these inks wouldn’t be a reasonable effort, and the 361 is
one of the writing implements I use most anyway. I also used a glass pen
to fill a couple of squares on the paper with more ink.
One side of each sheet was then covered with a strip of 300 g/m² black
paper (also from Clairefontaine), kept in place with three dots of
non-permanent two sided tape, put in the frame and set out in the sun on
the morning of 2026-03-20, the day of the spring equinox.
While I was filling the sheet for the lightfastness tests, I decided to
also prepare a second set of sheet, for a liquid resistance drop test.
On each line, beside the name of the ink, I added five sets of crossing
parallel lines, and let everything dry for a few days.
Then I used a syringe to put a drop of a liquid on each set of lines,
waited for it to be absorbed into the paper and to dry, at least
overnight, but sometimes also for a day or two (life happened), and then
looked at the results and did the next test.
The first liquid was water, with the usual wild difference between
washable and permanent inks, and all of the intermediate possibilities.
The second liquid was isopropyl alcohol, and I was surprised to see
that, with very few exceptions, most inks didn’t change at all. I
wonder whether that’s related to the fact that instead of forming a drop
it was absorbed almost immediately into the paper, and dried in a very
short time.
The third liquid was hydrogen peroxide: beside the individual results I
noticed that its column yellowed visibly; I wonder whether that means
that the paper I used has optical brighteners, and it will also yellow
under the sun: that wouldn’t be ideal, but it would also be a surprise,
for paper that is acid free and sold for arts.
The fourth liquid was citric acid, by mixing a bit less than a teaspoon
of citric acid granules in just enough very warm water (heated to 70°C,
i.e. the lowest temperature available on my kettle) to dissolve most of
the acid. I forgot that I had some old PH strips until one hour after
I’ve put the drop on the paper, and I don’t know whether something had
changed, but when I did remember about them it showed a deep red between
1 and 2. I don’t think I can trust those strips too much, however.
This backfired badly: the drop of citric acid never dried out, but
formed a sticky paste that prevented me from scanning the results,
and I’m not sure whether I’ll do the last test, which was supposed to be
household bleach.
Luckily I had scanned the partial results, and they are shown here.
After one full day with plenty of sun, nothing really had changed,
except possibly for a vague hint that the Herbin Bleu Myosotis may have
have been a bit lighter than it started, but it may also have been a
suggestion.
After three days, however, some results started to show, with the most
fugitive inks starting to be visibly changed, becoming either paler or
in some case duller.
And the full week showed more of that, with a few more inks starting to
show visible change.
These are the inks I’ve tested, and here I’ll add notes on the results,
as soon as they will be available, keeping this section updated.
When nothing is mentioned, it means that there were no changes, either
under the light or under the various liquids.
Lamy Sepia
Not resistant to water, the drop becomes an uniform colour spot.
After one week it started to be just slightly paler.
Sheaffer Skrip Red
Not resistant to water, the drop becomes an uniform colour spot.
After one week it started to be just slightly paler.
Waterman Audacious Red
Not resistant to water, the drop becomes an uniform colour spot.
After three days it started to be just slightly paler, after a week
visibly so.
Waterman Harmonious Green
Not resistant to water, the drop becomes an uniform colour spot; the
hydrogen peroxide drop looks a bit lighter than the one with just
water.
After one week it started to be just slightly paler..
Waterman Mysterious Blue
Not resistant to water, the drop becomes an uniform colour spot; the
hydrogen peroxide drop is significantly lighter and tends towards
green.
Waterman Serenity Blue
Not resistant to water, the drop becomes an uniform colour spot; the
hydrogen peroxide drop is almost completely bleached to a light yellow.
After one week it started to be a bit duller.
Visconti Blue
Not resistant to water, the drop becomes an uniform colour spot.
After one week it was visibly duller, looking darker than the
original.
Montblanc Royal Blue
Not resistant to water, the drop becomes an uniform colour spot; the
hydrogen peroxide drop is almost completely bleached to a light
yellow.
After one week it started to be just slightly duller..
Montblanc Mystery Black
Not resistant to water, the drop becomes an uniform colour spot.
Aurora Nero
Not resistant to water, the drop becomes an uniform colour spot.
Online Duft Blueberry
Not resistant to water, the drop looks very washed out, although a
hint of the original shape can be guessed; the hydrogen peroxide drop
is almost completely bleached to a light yellow.
After one week it was visibly paler and duller.
Diamine Forever Ink - Smoky Mauve
.
Diamine Forever Ink - Honey Pot
.
Diamine Forever Ink - Coral Blaze
.
Diamine Forever Ink - Red Ochre
.
Diamine Graphite
Not resistant to water, the drop becomes an uniform colour spot.
Diamine Rustic Brown
Not resistant to water, the drop becomes an uniform colour spot.
Diamine China Blue
Not resistant to water, the drop becomes an uniform colour spot; the
hydrogen peroxide drop is almost completely bleached to a light
yellow.
Diamine Inkvent Purple Edition - Glacier
Not resistant to water, there is a drop of uniform colour, but it
maintains a somewhat recognisable shade of the original shape.
Fountainfeder STEVE
Not resistant to water, there is a drop of uniform colour, but it
maintains a somewhat recognisable shade of the original shape.
Pilot Iroshizuku Syo Ro
Not resistant to water, there is a drop of uniform colour, but it
maintains a somewhat recognisable shade of the original shape.
Pilot Iroshizuku Shin-Kai
Not resistant to water, there is a drop of uniform colour, but it
maintains a somewhat recognisable shade of the original shape.
Rohrer & Klingner IG Ebony
Not resistant to water, there is a drop of uniform colour, but it
maintains a recognisable shade of the original shape; under
hydrogen peroxide the shade is significantly lighter.
KWZ IG Orange
Not resistant to water, the drop becomes an uniform colour spot; the
hydrogen peroxide drop is significantly bleached to a light orange.
Kallipos.de Schwarze Eisengallus-Tinte
Water stains the paper, leaving however the original shape quite
visible; is it almost completely bleached by hydrogen peroxide.
Kallipos.de Blaue Eisengallus-Tinte
Water stains the paper, leaving however the original shape quite
visible; is it almost completely bleached by hydrogen peroxide.
Rohrer & Klingner IG Salix
Water stains the paper, leaving however the original shape quite
visible; is it almost completely bleached by hydrogen peroxide.
Rohrer & Klingner IG Scabiosa
Water stains the paper with a significant purple spot, leaving
however the original shape quite visible; is is a bit bleached by
hydrogen peroxide, but still quite readable.
Pelikan Edelstein Tanzanite
Not resistant to water, the drop becomes an uniform colour spot, but
there is a visible trace of the original shape.
Montblanc Burgundy Red
Not resistant to water, the drop becomes an uniform colour spot, with
just a hint of the original shape; slightly bleached by hydrogen
peroxide.
Cifra inchiostro finissimo verde alla lavanda
Not resistant to water, the drop becomes an uniform colour spot;
quite bleached to a light yellowish green by hydrogen peroxide.
After one week it was visibly paler.
Sennelier Abstract acrylic ink 917 purple
.
The Feather Pen Ink
.
Eloquentia Inchiostro nero
.
DeAtramentis Document Blue
.
DeAtramentis Document BlueGrey
.
DeAtramentis Document Brown
.
DeAtramentis Document Fuchsia
.
DeAtramentis Document Grau
.
DeAtramentis Document Green Grey
.
DeAtramentis Document Light Grey
.
DeAtramentis Document Moosgrün
.
DeAtramentis Document Orange
.
DeAtramentis Document Purpurviolett
.
DeAtramentis Document Urban Sienna
.
KWZ Sheen Machine
Not resistant to water, the drop becomes an uniform colour spot; the
hydrogen peroxide bleached away the red sheen. This was one of the
only two inks to react to isopropyl alcohol, which caused a pale cyan
halo around the lines.
After three days it was still perfectly readable, but had visibly
lost some red sheen, after one week the red had completely gone and
it looked very dark blue (but still shiny)
KWZ Walk over Vistula
Not resistant to water, the drop becomes an uniform colour spot.
KWZ Warsaw Dreaming
Not resistant to water, the drop becomes an uniform colour spot.
Octopus Neon Violett
Water very lightly stains the paper, leaving however the original
shape quite visible. The other ink that reacted to isopropyl alcohol,
with a pale purple halo around the lines.
Octopus Write & Draw Elephant Black
.
Platinum blue black
Water stains the paper, leaving however the original shape quite
visible; it is significantly bleached by hydrogen peroxide.
Pelikan 4001 Brillant-Schwarz
Not resistant to water, the drop becomes an uniform colour spot.
Pelikan 4001 Blau-Schwarz
Water stains the paper, leaving however the original shape quite
visible; it is significantly bleached by hydrogen peroxide.
Pelikan 4001 Königsblau
Not resistant to water, the drop becomes an uniform colour spot, with
just a hint of the original shape; significantly bleached by hydrogen
peroxide.
After three days it had started to be slightly paler.
Herbin Bleu Myosotis
Not resistant to water, the drop becomes an uniform pink spot,
significantly bleached by hydrogen peroxide.
After three days it was already visibly paler, after one week it was
a pale grey.
Faber Castell Royal Blue
Not resistant to water, the drop becomes an uniform colour spot, with
just a hint of the original shape; significantly bleached by hydrogen
peroxide.
After three days it was slightly duller.
Koh-I-Noor Fountain pen ink blue
Not resistant to water, the drop becomes an uniform colour spot, with
just a hint of the original shape; significantly bleached by hydrogen
peroxide.
After three days it had started to be slightly paler, more so after
one week when it had also turned grey.
Koh-I-Noor Document Ink Blue
.
Koh-I-Noor Document Ink Black
Water leaves a very light stain, but the original shape doesn’t look
changed.
DeAtramentis Document Black
.
Waterman Intense Black
Not resistant to water, the drop becomes an uniform colour spot, with
a trace of the original shape still visible; very lightly bleached by
hydrogen peroxide.
Herbin Perle Noir
Not resistant to water, the drop becomes an uniform colour spot, with
a trace of the original shape still visible.
Parker Quink black
Not resistant to water, the drop becomes an uniform colour spot.
Platinum Carbon black
.
Rohrer & Klingner Documentus Black
.
Sailor Pigment Kiwaguro
.
Platinum Dyestuff Red
Not resistant to water, the drop becomes an uniform colour spot; very
lightly bleached by hydrogen peroxide.
Noodler’s Eternal Polar Blue
.
which would be spend the day covered by mostly closed
shutters anyway, because they receive quite a bit of direct sun, and
we don’t want that to enter the house during the summer.↩︎
I was reading a post on Alex Chan's
website1 that referenced the concept of
digital gardens,
a concept/analogy for organising information which dates back to the 90s.
This old concept is getting new traction today by contrasting the approach
with "endless stream" as used and abused by social media, but also how blogs
are typically presented.
This site, my homepage, has a blog, and that's the bit that most people who
interact with the site will experience. Partly, because it's the bit that gets
syndicated out: via feeds; on Planet
Debian and downstream from it; once upon a time on
Twitter; nowadays on the Fediverse.
However there's more to my homepage than that. The rest of it may be of little
interest to anyone beside me, but it's useful to me, at least. So I may switch
focus a little bit from mainly writing blog posts, and tend to the rest of the
garden a bit more.
Some recent seeding and pruning:
Recently my guest status at Newcastle University came up for renewal, so I
wrote down my goals in the Historic Computing Committee for the next year or
so, and put them here: nuhcc. I've also been pondering what I'm up to in
Debian at the moment, so took some time to add my current projects to
that page.
I'm reminded that I should really publish a "blog roll" of cool
blogs I'm following at the moment, of which Alex Chan's is one.↩
Interested in future updates? Follow me on mastodon at
@paul@soylent.green. Posts about
hz.tools will be tagged
#hztools.
It’s well known and universally agreed that radios are cool. Among the
contested field of coolest radios, Software Defined Radios (SDRs) are
definitely the most interesting to me. Out of all of my (entirely too many)
SDRs I own, the rtlsdr is still my #1. It’s just good. It’s a great price,
extremely capable, reliable, well-supported, and compact. Why bother with
anything else? Sure, it can’t transmit, uses a (fairly weird) 8 bit unsigned
integer IQ representation,
limited sampling rate, limited frequency range – but even with all that, it’s
still the radio I will pack first. Don’t get me wrong, I love my Ettus radios,
PlutoSDRs, HackRFs, my AirspyHF+ - they’re great! I just always find myself
falling back to an rtl-sdr, every time.
Perhaps the best reason to use an rtlsdr is the absolutely mind-boggling
amount of cool stuff people have written for it. The rtlsdr API is super easy
to use, widely supported if you’re building on top of existing radio processing
frameworks – it’s still a shock to me when something omits rtlsdr support.
sparky
Over the last 7 years, I’ve been learning about radios – I got my ham radio
license (de K3XEC), hackedonsomecoolstuff where I’ve
learned how radios work by “doing”, and even was lucky enough to give my first
rf-centric talk at districtcon.
Embarrassingly, I still haven’t gotten around to learning how the fancy stuff
like GNU Radio works. I’m sure I’m going to love
it when I do.
As part of this, I’ve also cooked up some very unprofessional formats and
protocols I use for convenience. Locally, all my on-disk captures are stored in
rfcap or more recently arf (post on this coming
soon), while direct SDR access at my house is almost entirely a mix of
the widely used rtl-tcp protocol, and my
“riq” protocol (post on this coming soon). Both rtl-tcp and riq operate
over the network, so I don’t have to bother with plugging things into USB ports,
and I can share my radios with my friends.
All of that work sits in my current generation of radio processing code,
“sparky” (a reference to
spark-gap transmitters),
which is a heap of Rust, supporting everything from no_std for embedded
experiments, conditional support for interfacing with all the radios I
own, and tokio-based async support in addition to blocking i/o
for highly concurrent daemons. This quickly advanced beyond my old Go-based
code (hz.tools/go-sdr), which I archived
so I can focus on learning. I still think Go is a great language to write RF
code in – but I can’t focus on that tech tree anymore.
Of course, this now poses a new problem – no one supports my format(s) or
radio protocol(s), since, well, I’m the only one using them. I’ve committed a
fair amount of my hardware to this setup, and yanking it from the rack to try
something out does pose a bit of a pickle. This isn’t a huge deal for learning,
but it does make it tedious to try out something from the internets.
librtlsdr.so
Thankfully, Rust has robust support for
wrap[ping itself] in a grotesque simulacra of C’s skin and mak[ing its] flesh undulate,
which is an attractive nuisance if i’ve ever seen one. Naturally, my ability
to restrain myself from engaging in ill-advised rf adventures is basically
zero, so it’s time to do the thing any similarly situated person would do –
reimplement the API and ABI of librtlsdr.so, backed with sparky instead.
Since enumeration of devices is going to be annoying (specifically, they’re
over the network), I decided early-on to rely on an explicit list of
devices via a configuration file. I’d rather only load that once so programs
don’t get confused, so I opted to use a
CTOR
to run a stub when the ELF is linked at runtime.
Next, it’s time to start with the basics. Opening and closing a handle using
rtlsdr_open and rtlsdr_close. Given we don’t control the runtime, and the
rtl-sdr device handle is opaque (for good reason!), I opted to smuggle a rust
Box<Device> non-FFI safe heap-allocated struct through the device handle
pointer, and let C take ownership of the Box. No one should be looking in
there anyway.
// lightly edited for clarity
#[unsafe(no_mangle)]pubunsafeextern"C"fnrtlsdr_open(dev: *mut*mut Handle, index: u32) -> int {
let config =&CONFIG.device[index asusize];
let sdr =match config.load() {
Ok(v) => v,
Err(err) => {
return-1;
}
};
let handle = Box::new(Handle { config, sdr });
unsafe { *dev = Box::into_raw(handle) };
0}
#[unsafe(no_mangle)]pubunsafeextern"C"fnrtlsdr_close(dev: *mut Handle) -> int {
let dev =unsafe { Box::from_raw(dev) };
drop(dev);
0}
With that in place, we can chip away at the API surface, translating calls
as best as we can. I won’t bother listing it all, since it’s not very
interesting – but here’s an example implementation of rtlsdr_set_sample_rate
and rtlsdr_get_sample_rate. These calls are translating from an rtl-sdr
frequency (which is a u32 containing the value as Hz) into a sparky Frequency
type, and invoking get_sample_rate or set_sample_rate on the device’s
rust handle. Since each device implements the sparky Sdr trait, the actual
underlying device doesn’t matter much here.
#[unsafe(no_mangle)]pubunsafeextern"C"fnrtlsdr_set_sample_rate(dev: *mut Handle, rate: u32) -> int {
let dev =unsafe { &mut*dev };
let rate = Frequency::from_hz(rate asi64);
iflet Err(err) = dev.sdr.set_sample_rate(dev.channel, rate) {
return-1;
}
0}
#[unsafe(no_mangle)]pubunsafeextern"C"fnrtlsdr_get_sample_rate(dev: *mut Handle) -> u32 {
let dev =unsafe { &mut*dev };
let freq =match dev.sdr.get_sample_rate(dev.channel) {
Ok(freq) => freq,
Err(err) => {
return0;
}
};
freq.as_hz() asu32}
After repeating this process for the rest of the stubs I could (and otherwise
setting error conditions if the functionality is not supported), I was ready to
try it out. Within sparky, I patched my “MockSDR” (basically a Sdr traited
Mock type) to implement the same testmode IQ protocol that the RTL-SDR has, and
decided to see if rtl_test from apt without any changes could be fooled.
$ rtl_test
No supported devices found.
Great, cool. No devices plugged in. Looks great. Let’s try it with my
librtlsdr.soLD_PRELOAD-ed into the binary first:
$ LD_PRELOAD=target/release/librtlsdr.so rtl_test
Found 1 device(s):
0: hz.tools, mock sdr, SN: totally legit no tricks
Using device 0: sparky mock sdr
Supported gain values (0):
Sampling at 2048000 S/s.
Info: This tool will continuously read from the device, and report if
samples get lost. If you observe no further output, everything is fine.
Reading samples in async mode...
^CSignal caught, exiting!
User cancel, exiting...
Samples per million lost (minimum): 0
$
Outstanding. Even more outstandingly, if I change my testmode implementation to
skip samples, rtl_test correctly reports the errors – I think it’s showing
promise! On to try the real endgame here – let’s have our new librtlsdr.so
connect to an rtl-tcp endpoint and see if rtl_fm works:
LD_PRELOAD=target/release/librtlsdr.so \
rtl_fm -d 1 -s 120k -E deemp -M fm -f 90.9M | \
ffplay -f s16le -ar 120k -i -
Found 2 device(s):
0: hz.tools, mock sdr, SN: totally legit no tricks
1: hz.tools, rtl-tcp, SN: node2.rf.lan:1202
Using device 1: sparky rtltcp node2
Tuner gain set to automatic.
Tuned to 91170000 Hz.
Oversampling input by: 9x.
Oversampling output by: 1x.
Buffer size: 7.59ms
Sampling at 1080000 S/s.
Output at 120000 Hz.
And there it was! Not the best audio quality (mostly due to my inability to
correctly read the rtl_fm manpage to tune the filter and
downsample/oversampling rates to audio), but it’s definitely passable.
I figured I’d try something that was a bit more interesting next – gqrx,
since it’s super handy, I use it a ton, and will definitely amuse me to no
end. To my surprise and delight, LD_PRELOAD=target/release/librtlsdr.so gqrx
wound up running, and I saw my devices pop right up in the setting menu:
Huge. Huge. Amazing. It did crash as soon as I tried to actually use the
radio, but after fixing a few dangling bugs in the API surface (and some
assumptions I think some underlying gnuradio driver may be making that I need
to double check in the code), I was able to get a super solid stream of
broadcast fm radio, with gqrx being none the wiser. It thought it was
“just” talking to the device it knows as rtl=1.
Nice. I can’t wait to try this with the rest of the rtl-sdr based tools I like
having around using my riq protocol next. I don’t think that’ll be worth a
post, but hopefully I’ll get around to publishing details on that stack next.
epilogue
Well. That’s it. End of story. A bit anti-climatic, sure. While this new shim
will provide me endless minutes of mild amusement, I could see using this to
expose my sparky testing utilities via librtlsdr.so – my “mock sdr” driver
allows for replaying captures off disk, which could be interesting to make sure
that signals are still properly decoded after changes, or instrument
performance changes (via SNR, BER, packets observed, etc) on reference samples
I have on my NAS. Maybe that’ll come in handy one day!
Truth be told, I’m not sure I actually want to encourage anyone to do this for
real (although I think I’ll definitely be using it on my LAN to see what
happens). I also don’t have a repo to share – I don’t particularly feel with
dealing with the secondary effects of publishing sparky (and sparky-rtlsdr)
yet, since i’m still getting my feet under me on the radio aspect of all this.
I’ll be sure to post updates if anything changes with this here (tagged
sparky) and at
@paul@soylent.green.
I can’t wait to post more about some of the odd sidequests (like this one!)
i’ve completed over the last few years – I’ve been waiting to feel
confident that my work has matured and was withstood the new problems i’ve
thrown at it, and it largely has.
It’s my hope that these projects (and this project in particular) has provided
a glimpse into the world of software defined radio for my systems friends, and
a bit about systems for my radio friends. It’s not all magic, and I hope
someone out there feels inclined to have some fun with radios themselves!
A few months ago, in June 2025, I joined Chainguard, a company focused on software supply chain security.
This post is a reflection on how I got here, what I’ve been doing, and why this role feels like a natural
fit for my interests in Linux and open source technology.
The company and its mission
Chainguard’s mission is to make the software supply chain secure by default. The company is built around
the idea that the software we all depend on — from operating system packages to container base images — carries
hidden risk in the form of vulnerabilities, unverified provenance, and untrusted build processes.
The company is perhaps best known for Chainguard Images: a catalog of minimal, hardened container
base images that are continuously rebuilt and kept free of known CVEs. Each image is accompanied by a signed
SBOM (Software Bill of Materials) and a verifiable provenance attestation, making it possible
to cryptographically verify what went into a given image and how it was built.
Chainguard has an extensive catalog of software, and maintaining it up-to-date and CVE-free is a significant
engineering challenge.
What I do
I joined the Chainguard Sustaining Engineering team as a Senior Software Engineer. We are responsible
for maintaining packages and images in the software catalog up-to-date and CVE-free. The core of the business, basically.
We focus on the horizontal dimension of the catalog (pretty much all packages and images).
With +30,000 packages and +2,000 images, this is indeed an interesting task.
My role as Debian Developer, and my experiencie in the Debian LTS project was extremely valuable when joning this
new team.
Looking ahead
Software supply chain is truly a deep topic, gaining more and more relevance every day, especially as new technologies emerge
and get adopted everywhere.
Since early in my career, I saw a recurrent problem of how companies, enterprises, or even governments, relate to and consume
open source software, in a reliable, secure way. I believe Chainguard is doing the right things in the ecosystem,
and I’m happy to be participating in the effort.
This is an experimental feature that, for the first time, brings full ECH
support to curl on Debian using OpenSSL.
Starting with curl 8.19.0-3+exp2 (Debian Experimental), you can now use
ECH, with HTTPS-RR and DoH for maximum privacy.
curl 8.19.0-3+exp2 is quite fresh at the time of writing, bear in mind that your
repository might not have synced the package yet, all mirrors should have it by
March 27th 14:00 UTC.
# defo.ie is a test server that confirms whether ECH was successfully usedcurl -v --ech hard https://defo.ie/ech-check.php# For Encrypted Client Hello (ECH) + DNS over HTTPS (DoH)curl -v --ech hard --doh-url https://1.1.1.1/dns-query https://defo.ie/ech-check.php
"--ech hard" tells curl to refuse the connection entirely if ECH cannot be negotiated.
Or, if you would like to try it out in a container:
podman run debian:experimental /bin/bash -c 'apt install --update -t experimental -y curl && curl -v --ech hard --doh-url https://1.1.1.1/dns-query https://defo.ie/ech-check.php'
(in case you haven't noticed, apt now has the --update option for the
upgrade and install commands)
Encrypted Client Hello (rfc9849) encrypts the
"which website are you connecting to?" part of the TLS handshake that was
previously visible in plaintext.
HTTPS-RR (rfc9460) is a DNS record type that
publishes connection parameters for a service, including the public key clients
need to perform ECH.
DNS Over HTTPS (rfc8484) encrypts DNS queries
by tunneling them over HTTPS, hiding what domains you're looking up from
network observers.
When all three operate together over a CDN with shared IP space, the target
domain name is hidden from passive observers; the HTTPS-RR record is queried
over DoH in order to retrieve the ECH key
(rfc9848) for the TLS handshake.
Seems like quite an important feature, and in fact the major browsers have it
enabled for some time now, the trick is that they do not use OpenSSL (Chrome
uses BoringSSL and Firefox uses NSS).
For everyone else, the only option is to patch OpenSSL or wait until 4.0.0 is
released, and so part of the reason Debian is the first distro to enable it
(curl + OpenSSL + ECH) is that the OpenSSL maintainer (Sebastian Andrzej
Siewior) packaged the alpha release just 3 days after it was published.
Do not forget that ECH support is experimental and currently relies on the
alpha release of OpenSSL.
wcurl Gets It Too
Considering wcurl is just a wrapper on curl, it gets
the feature for free:
wcurl --curl-options="--ech hard --doh-url https://1.1.1.1/dns-query" $URL
If you're using wcurl, you don't want to have to set parameters, this is just
to show that the feature is there and if you have a .curlrc file, it can
enable the feature seamlessly.
Other Debian Releases
Given the ECH feature requires OpenSSL >= 4, it will not make it to Debian 13,
having a small chance of going to Debian 13 Backports (emphasis on small).
It should get to Debian Unstable and Debian Testing within the next couple of
months as the OpenSSL GA release happens and gets packaged, but you should be
able to install the package from Experimental in your Unstable and Testing
systems without issues. It will also be in Debian 14 once it becomes the new Stable.
Shoulders of Giants
Stephen Farrell's presentation from OpenSSL Conference 2025 has a lot of
background on the work involved:
They have been working on implementing ECH in open-source projects for years,
something as big as this doesn't happen without lots of people dedicating both
their paid and free times over it.
I ended up being the person who enabled it on Debian, which was pretty much the
least amount of work between everyone involved, but hey it's fun flipping the
switch and telling you about it.
Attendance was really good, and as you can imagine one of the topics of
discussion was ECH, in which it was pointed out that having OpenSSL 4 was
the main requirement but besides it nothing unusual was needed.
In Debian Experimental, we have been enabling HTTPS-RR since March 2025, and
OpenSSL 4.0.0 alpha was packaged just recently (2026-03-13) by Sebastian
Andrzej Siewior, it's time for the next step.
The curl distro meeting was just the motivation I needed to go ahead and
enable it in Debian Experimental, so as part of our Debian Brasil Weekly
Meetings I've prepared and uploaded the changes, while Carlos Henrique Lima
Melara worked on addressing a recent test regression for Debian Unstable.
Unfortunately sergiodj couldn't join and I'm sure he's jealous of the hacking
session now.
Appendix
While writing this, I've noticed one of the authors of the CloudFlare blogpost
is the previous curl maintainer on Debian; Alessandro Ghedini let me take over
the maintenance back in 2021 and today curl is maintained by a team of 4
people, it's nice to see Alessandro's involvement.
The LinuxCNC project continues
to thrive. I believe this great software system for numerical control
of machines such as milling machines, lathes, plasma cutters, routers,
cutting machines, robots, and hexapods would benefit even more from
in-person developer gatherings. Therefore, we plan to organise another
gathering this summer as well.
We invite you to a small LinuxCNC and free software fabrication
workshop/gathering in Norway this summer, over the weekend starting
June 26th, 2026. As last year, we maintain a slightly broader scope
and welcome people outside the LinuxCNC community. As before, we
suggest to organise it as an
unconference,
where participants create the program upon arrival.
The location is a metal workshop 15 minutes' drive from Gardermoen
airport (OSL), with plenty of space and a hotel just 5 minutes away by
car. We plan to fire up the barbecue in the evenings. Please let us
know if you would like to join. We track the list of participants on
a simple pad.
Please add yourself there if you are interested in joining.
Our friends over at the
TS Robotics
team at the University of Oslo have offered to handle any money
involved with this gathering, that is, holding sponsor funds and
paying the bills. We hope to secure enough sponsors to cover food, lodging,
and travel. So far, Debian has offered to sponsor part of the
expenses, which should cover food and a bit more. Please get in touch
if you would like to help sponsor the gathering.
As usual, if you use Bitcoin and wish to show your support of my
activities, please send Bitcoin donations to my address
15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
At the end of last year I uninstalled the Twitter app on my phone.
In the past Twitter used to be very useful for providing feedback to large organisations. I had responses from supermarkets, chain restaurants, online stores, major computer companies, and even the IT department of a court. In recent times I have had less responses from corporations which significantly reduces the value of Twitter to me and to many other users. It seems that Elon’s management style has discouraged not only advertising but also all forms of corporate interaction. Messing up the check mark on accounts to make it harder to work out which is a real corporate
Since Elon bought it Twitter has been increasingly pushing conservative Tweets and has done little to stop bot accounts. The incidence of useful discussions has steadily decreased. I know people who have quit Twitter entirely due to opposition to Elon, I am not doing that. I finally decided to stop using Twitter in any serious way when the notifications on my phone about popular Tweets started only being about Tweets from conservative influencers and Elon. This was obviously not any algorithm based on Tweets I was liking, it was based on political decisions. I didn’t uninstall the app due to political disagreement, I uninstalled it because it was through deliberate design promoting material that any algorithm would know was something I wouldn’t either like or “like”.
I still announce new blog posts on Twitter for my 198 followers at the same time as announcing them on Mastodon and Facebook. I get the most reactions to such announcements on Mastodon, the second most on Facebook, and hardly any on Twitter. I’m wondering how long it will be worth announcing blog posts on Twitter or whether I should stop now.
I am sure that many other people are making similar decisions and this is going to affect Twitter overall.
The web site www.russellcoker.com has information on all the ways of following me.
AI sure is a hot topic right now, and I see a lot of people arguing about it. To a lot of people around here, I’m the “computer person” they know and I get asked a lot about AI.
I’m going to suggest a lot of things can be true at once. For instance:
LLMs are changing how we work and will continue to do so.
LLMs are vastly over-hyped by vested interests, and may be in a bubble.
Or how about:
Huge investment in GenAI is having many negative consequences, ranging from environmental to causing affordability problems in many industries that use hardware (ie, everywhere)
Useful results can be had from models that run on local hardware, even battery-powered hardware, which may have negligible harm or even some benefit
And:
GenAI is further concentrating wealth and power in megacorps, with the effect of squeezing out the smaller players even more.
GenAI is lowering the cost of entry for people without a lot of resources already.
I have sympathy for the naysayers; those that say it’s nothing but a stochastic parrot. But I don’t have a lot of sympathy for the naysayers that deny ever using it; you can’t form a credible argument against something without having an understanding of it informed by experience.
I also have sympathy for the cheerleaders. I have seen some impressive things from AI; for instance, a story from an engineer who has a child with a rare disease without a credible cure. The engineer did a lot of research on it, started feeding research papers into AI to analyze, and the AI started finding correlations between different areas of research that humans hadn’t yet found — leading to a positive result for the child.
To be fair, I have rarely seen an AI deliver a 100% correct answer on anything with any real level of complexity. I have seen it both waste more time than it saves, and save a ton of time.
My point here is: It is neither always fantastic nor always terrible.
Let me talk you through an example.
I am a fan of inbox zero for email. That is, the inbox should be empty. Unfortunately, mine has 8000 messages in it. According to the oldest messages in my inbox, I last had inbox zero 8 years ago. But really, only a handful are older than 2020. I guess something must have happened that year…
I’ve been chipping away at this for quite some time now. The problem is, there are certain emails in there that really do still need some action – maybe it’s photos to save off into our photo collection, for instance. But when looking at things sorted by date or thread, there are old shipping confirmations next to phishing attempts and family photos. One can’t just scan down the list.
I’ve tried all the usual tricks, most of which involve selecting groups of message that are easy to bulk erase, or at least easy to scan visually for the occasional thing worth saving. Sort by sender or subject line, for instance. Then I can, for instance, delete all the old messages from the shopping sites I commonly use all at once. But then they start using different senders and different subject lines and that doesn’t get all of them. I’ve tried keyword searches for this sort of thing too. Still, that got me down to about 8000 messages.
So I thought: why not see if an LLM could help me classify these? Maybe it could categorize them, and then I could look at emails grouped by category.
I have one machine with a discrete GPU, an Nvidia RTX 4070. It’s a desktop machine I don’t use all that often. But I set up Ollama on it, running in a Docker container. Ollama runs models locally.
I should also mention at this point that we are solar-powered, and this time of year is a time of peak production of excess solar, because it is sunny and not much heat or AC is required. So that machine is solar-powered and isn’t causing environmental harm. In any case, charging the EV uses much more power than that GPU.
I figured I would do this in two passes. First, ask the LLM to classify each message (or a sampling of them would probably work too), letting it pick its own categories for each. Then, look at the patterns that emerge and give it a single, much smaller, set of broad categories to use and rerun it over that.
Then I can easily select messages from my Maildirs by category and process them in bulk.
I used open-interpreter pointing to that GPU on my network to help me write the scripts for this. It didn’t get things right on its own; for instance, it didn’t call the Ollama API correctly, and insisted on appending “/cur” to the path to the Maildir (which was not going to fly with Python’s maildir module). It took roughly an hour to classify those 8000 messages (or, as I had it do, the first 2000 characters of them), and then the same to do it a second time. I had it output lines in the form of “filename\tcategory” and hand-wrote the shell script that processed those.
In the end, was it useful? Yes, quite. Its classifications weren’t perfect (and it didn’t even follow my prompt perfectly; sometimes it would give me a long discussion on why it picked a certain category rather than just that category, and occasionally it picked categories not on the list). But then, neither were my manual keyword searches. So far I’ve gotten rid of nearly 1000 more messages. Several categories were a “visual scan for sanity and then delete all” sort of thing.
My emails never left my network. I didn’t rely on a cloud AI to process them. I didn’t contribute to global warming (this may have even been a case of saving energy, since it no doubt will offset quite a bit of manual time that would keep screens and room lights energized and so forth). I used about as much energy as watching a movie on a TV.
Did it complete the task for me entirely autonomously? Also no. AI isn’t a mind reader and it can’t possibly evaluate exactly what my thought process would be for a given task. But it can do a decent enough job to save me some time.
Still, this didn’t require hyperscaler datacenters. AI even runs on-phone (Google Translate being one of the most useful AI-driven apps I’ve ever seen, and it can run on-device).
A Shadow in Summer is a high fantasy novel, the first of (as the
name implies) a completed four-book series. Daniel Abraham is perhaps
better known as half of the writing pair behind James S.A. Corey, author
of the Expanse series. This was his first
novel.
Otah was the sixth son of a Khai, sent like many of the unwanted later
children of the powerful to learn the secrets of the andat and be trained
as a poet. He learned his lessons well enough to reject the school and its
teachings and walk away.
Amat Kyaan has worked her way up from nothing to become the senior
overseer of the foreign Galtic House Wilsin in the sun-drenched port city
of Saraykeht. Liat is her apprentice, distracted by young love. Maati is a
new apprentice poet, having endured his training and sent to learn from
Heshai how to eventually hold the andat Removing-The-Part-That-Continues,
better known as Seedless. None of them know they will find themselves
entangled in a plot to destroy the poet of Saraykeht and, through him, the
city's most potent economic tool.
A poet in this world is not what we would think of a poet. They are, in
essence, magical slave-drivers who capture the essence of an andat, a
spirit embodying an idea that is coerced into the prison of volition and
obedience by the poet. The andat Seedless, the embodiment of the concept
of removing the spark of life, is central to the economic wealth of
Saraykeht in a way that is startling in its simplicity: Seedless can
remove the seeds from a warehouse full of cotton at a thought. This gives
Saraykeht a massive productivity advantage in the cotton trade.
Seedless is also a powerful potential weapon. What he can do to cotton, he
could as easily do to any other crop, or to people. The Galts are not fond
of the independence and power of Saraykeht, but as long as the city
controls a powerful andat, they do not dare to attack it directly.
Indirectly, though... that's another matter.
This is one of those fantasy novels with meticulous and thoughtful
world-building, careful and evocative prose, and a complex ensemble cast
of interesting characters that the novel then attempts to make utterly
miserable and complicit in their own misery. There should be a name for
this style of writing. It's not tragedy because the ending is not tragic,
precisely. It's not magic realism; the andats are openly magical, which
makes this clearly high fantasy. But Abraham approaches the story from the
type of realist frame that considers the pain and desperation of the
characters to be more interesting than their ability to overcome
challenges.
Amat starts the story as an admirable, sharp-witted expert manager, so her
life is destroyed and she's subjected to sexual violence. Heshai loathes
himself and veers between a tragic figure and a wastrel as the story
systematically undermines opportunities for redemption. Maati is young and
idealistic, so of course every character in the book sets out to crush his
idealism under the weight of unforeseen consequences. There is a sad and
depressing love triangle, because this is exactly the sort of book that
has a sad and depressing love triangle. At the end of the novel, everyone
who survives is older and wiser in the sense that some stories seem to
think wisdom comes from the accumulation of trauma.
I find books like this so immensely frustrating because their merits are
so clear. The world-building is careful and detailed in a way that
includes economic systems, unlike so much fantasy. It is full of small,
intriguing touches, such as the use of posture and gesture to communicate
the emotional valence of one's words. Abraham understands the moral
implications of poets and andats and the story tackles them head-on. The
writing flows beautifully and gave me a strong sense of the city. I wanted
to like this book for the obvious skill that went into it, and sometimes I
even managed.
And yet, it's taken me three months to finish A Shadow in Summer
because I simply do not want to spend this much time around miserable
people. I would get through one or two chapters in a night and then wanted
to read something happy or defiant or heroic, rather than watching
slow-motion train wrecks intermixed with desperate attempts to navigate
stifling layers of immoral systems. It's not that the story lacks a moral
compass. The characters are sincerely trying to make the world a better
place, with some success. It even delivers a happy ending of sorts. But so
much of the journey was watching the lives of the characters fall apart.
I am completely unsurprised that some people loved this book. I'm still
intrigued enough by the world-building that I'm half-tempted to try to
read the sequel even after having to drag myself through this one. I had a
similar reaction to Abraham's The
Dragon's Path, though, so I think Abraham is just not for me. I may get
back to the Expanse at some point, but having to drag myself through both
of his solo novels I've tried, in two different series, probably indicates
an incompatibility between author and reader. That's a shame, given the
quality of the writing.
Followed by A Betrayal in Winter.
Content notes: Sexual and reproductive violence as significant plot
elements.
This needs to be clear: systemd is under attack by a trolling campaign orchestrated by fascist elements. Nobody is forced to like or use systemd, but anybody who wants to pick a side should know the facts.
Recently, the free software Nazi bar crowd styling themselves as "concerned citizens" has tried to start a moral panic by saying that systemd is implementing age verification checks or that somehow it will require providing personally identifiable information.
This is a lie: the facts are simply that the systemd users database has gained an optional "date of birth" field, which the desktop environments may use or not as they deem appropriate. Of course there is no "identity verification" or requirements to provide any data, which in any case would not be shared beyond authorized local applications.
While the multiple recent bills proposing that general purpose operating systems implement age verification mechanisms are often concerning, both from a social and technical point of view, this is not the topic being discussed here. They are often suboptimal, but for a long time I have been opposing attempts to implement parental control at the network level and argued that it should be managed locally, by parents on their own machines: I cannot see why I should outright reject an attempt to implement the infrastructure to do that.
If we want to keep age-appropriate controls out of the hands of centralized authorities, the alternative is giving families the means to manage it themselves: this is what this field enables. Whether desktop environments use it for parental controls, for birthday reminders, or for nothing at all, is their users' decision.
By the way, the original UNIX users database has allowed storing PII in the GECOS field since it was invented in the '70s. Similar fields are also specified by many popular LDAP schemes: adding such an optional field is consistent with the UNIX tradition.
And while we are at it, let's also refute the other smear campaign started by the same people: the systemd project is not accepting "AI slop". What happened is that a documentation file for the benefit of coding agents was added to the repository. To be clear: agents still cannot submit merge requests. The file itself remarks that all contributions must be reviewed in detail by humans, and this is basically the same policy used by the Linux kernel.
Note: I have not published blog posts about my academic papers over the past few years. To ensure that my blog contains a more comprehensive record of my published papers and to surface them for folks who missed them, I will periodically (re) publish blog posts about some “older” published projects. This post draws material from a previously published post by Kaylea Champion on the Community Data Science Blog.
Taboo subjects—such as sexuality and mental health—are as important to discuss as they are difficult to raise in conversation. Although many people turn to online resources for information on taboo subjects, censorship and low-quality information are common in search results. In two papers I recently published at CSCW—both led by Kaylea Champion—we presented a series of analyses showing how taboo shapes the process of collaborative knowledge building on English Wikipedia.
The first study is a quantitative analysis showing that articles on taboo subjects are much more popular and are the subject of more vandalism than articles on non-taboo topics. In surprising news, we also found that they were edited more often and were of higher quality!
Short video of Kaylea’s presentation of the work given at Wikimania in August 2023.
The first challenge we faced in conducting this work was identifying taboo articles. Kaylea had a brilliant idea for a new computational approach to doing so without relying on our individual intuitions about what qualifies as taboo (something we understood would be highly specific to our own culture, class, etc). Her approach was to make use of an insight from linguistics: people develop euphemisms as ways to talk about taboos (i.e., think about all the euphemisms we’ve devised for death, or sex, or menstruation, or mental health).
We used this insight to build a new machine-learning classifier based on English Wiktionary definitions. If a ‘sense’ of a word was tagged as euphemistic, we treated the words in the definition as indicators of taboo. The end result was a series of words and phrases that most powerfully differentiate taboo from non-taboo. We then did a simple match between those words and phrases and the titles of Wikipedia articles. The topics were taboo enough that we were a little uncomfortable discussing them in our meetings! We built a comparison sample of articles whose titles are words that, like our taboo articles, appear in Wiktionary definitions.
In the first paper, we used this new dataset to test a series of hypotheses about how taboo shapes collaborative production in Wikipedia. Our initial hypotheses were based on the idea that taboo information is often in high demand but that Wikipedians might be reluctant to associate their names (or usernames) with taboo topics. The result, we argued, would be articles that were in high demand but of low quality.
We found that taboo articles are thriving on Wikipedia! In summary, we found that in comparison to non-taboo articles:
Taboo articles are more popular (as expected).
Taboo articles receive more contributions (contrary to expectations).
Taboo articles receive more low-quality contributions (as expected).
Taboo articles are higher quality (contrary to expectations).
Taboo article contributors are more likely to contribute without an account (as expected), and have less experience (as expected), but that accountholders are more likely to make themselves more identifiable by having a user page, disclosing their gender, and making themselves emailable (all three of these are contrary to expectation!).
Image of the estimated qualiy of articles of the four articles in the second mixed-methods paper. Extreme dips reflect periods of frequent vandalism.
Kaylea attempted to understand these somewhat confusing results by designing a fantastic mixed-methods analysis that sought to unpack some of the nuance missing in the quantitative analysis by delving deep into the “life histories” of four articles on English Wikipedia: two on taboo topics related to women’s anatomy (Clitoris and Menstration) and two nontaboo articles chosen for comparison (Cell membrance and Philip Pullman).
Although the findings from the analysis can be difficult to summarize succinctly (as with many qualitative studies), we showed how the taboo example articles’ success was hard-won amid real challenges and attacks. The paper describes how challenges were overcome through resilient leadership, often provided by a single dedicated individual. The paper provides a template for how taboo can be—and frequently is—overcome by dedicated Wikipedians in ways that provide useful knowledge resources in real demand.
For more details, visualizations, statistics, and more, we hope you’ll take a look at our papers, both linked below.
The full citation for the papers are: (1) Champion, Kaylea, and Benjamin Mako Hill. 2023. “Taboo and Collaborative Knowledge Production: Evidence from Wikipedia.” Proceedings of the ACM on Human-Computer Interaction 7 (CSCW2): 299:1-299:25. https://doi.org/10.1145/3610090. (2) Champion, Kaylea, and Benjamin Mako Hill. 2024. “Life Histories of Taboo Knowledge Artifacts.” Proceedings of the ACM: Human-Computer Interaction 8 (CSCW2): 505:1-505:32. https://doi.org/10.1145/3687044.
Dark Class is the fifth novel (not counting the
skippable novella) in Michelle Diener's Class 5
romantic science fiction series. As with the previous novels, this follows
romance series conventions: There are new protagonists, but characters
from the previous books make an appearance. It's helpful but not that
necessary to remember the details of the previous books; the necessary
background is explained enough to follow the story.
By now, series readers know the formula. Yet another Earth woman was
secretly abducted by the Tecran, encounters a Class 5 ship, and finds a
way to be surprisingly dangerous and politically destabilizing. This time,
Ellie has been mostly unconscious since her abduction and awakes in a
secret Tecran base after the Tecran have all been murdered. There is a
Class 5 AI involved, but not a full ship; instead, Dark Class picks
up (or, arguably, manufactures) a loose end from Dark Minds. Other than that break from the formula, you know what
to expected by now: a hunky Grih, a tricky political standoff, a
protective Class 5, a slow-burn romance, and a surprisingly capable
protagonist who upends politics through plucky grit and refusal to
tolerate poor treatment. Oh, and a new selection of salvaged clothing and
weapons to make Ellie beautiful and surprisingly dangerous.
If you are this far into the series, you probably like the formula. That's
my position. I don't care about the romance, but something about the
prisoner to threat evolution of the kidnapped protagonists and the growing
friendship with an AI makes me happy. This is not great literature, but it
is reliably entertaining with a guaranteed victorious protagonist and
happy ending, making it a comfortable break from more difficult books with
emotionally wrenching scenes.
Dark Class is one of the better executions of the formula because
it has long stretches of my favorite parts of these books: exploration of
mostly-abandoned surroundings for neat gadgets while the AI and the
protagonist slowly build a relationship of mutual respect. This book has
bonus drones with minds of their own and an enigmatic alien spaceship that
provides a fun mid-novel twist. The Tecran and the Grih repeatedly
underestimate Ellie and are caught by surprise at dramatically satisfying
moments. It's just fun to read, and I save this series for when I need
that type of book.
As with the other books of the series, Diener's writing is serviceable but
not great. She repeats herself, uses way too many paragraph breaks for
emphasis, and is not going to win any literary awards for prose quality.
The series is in the upper half of self-published works, and I've
certainly read worse, but either the formula will click with you or it
won't. If it doesn't, the prose is not going to salvage the book.
There is some development of the series plot, but it's mostly predictable
fallout from Dark Matters. This book is
mostly tactical and smaller in scale. I am a little curious where Diener
is going with political developments, since the accumulated Earth women
and Class 5 ships are in some danger of becoming a sort of shadow
government through sheer military power, but I'm dubious this series will
have enough political sophistication to dig into the implications. It's
best enjoyed as small-scale episodic wish fulfillment for female
protagonists, and that's good enough for me.
If you've read this far in the series, recommended; this is one of the
stronger entries.
Followed by Collision Course, which breaks the title convention for
the series.
I often need a quick calculation or a unit conversion. Rather than reaching for
a separate tool, a few lines of Zsh configuration turn = into a calculator.
Typing = 660km / (2/3)c * 2 -> ms gives me 6.60457 ms1 without
leaving my terminal, thanks to the Zsh line editor.
The main idea looks simple: define = as an alias to a calculator command. I
prefer Numbat, a scientific calculator that supports unit conversions.
Qalculate is a close second.2 If neither is available, we fall back to
Zsh’s built-in zcalc module.
As the alias built-in uses = as a separator for name and value, we need to
alter the aliases associative array:
With this in place, = 847/11 becomes numbat -e 847/11.
The quoting problem
The first problem surfaces quickly. Typing = 5 * 3 fails: Zsh expands the *
character as a glob pattern before passing it to the calculator. The same issue
applies to other characters that Zsh treats specially, such as > or |. You
must quote the expression:
$ ='5 * 3'15
We fix this by hooking into the Zsh line editor to quote the expression
before executing it.
Automatic quoting with ZLE
Zsh calls the line-finish widget before submitting a command. We hook a
function that detects the = prefix and quotes the expression:
_vbe_calc_quote(){case$BUFFERin"="*)typeset-g_vbe_calc_expr=$BUFFER# not used yetBUFFER="= ${(q-)${${BUFFER#=}# }}";;esac}
add-zle-hook-widgetline-finish_vbe_calc_quote
When you type = 5 * 3 and press ↲, _vbe_calc_quote strips the =
prefix, quotes the remainder with the (q-) parameter expansion flag,
and rewrites the buffer to = '5 * 3' before Zsh submits the command. As a
bonus, you can save a few keystrokes with =5*3! 🚀
You can now compute math expressions and convert units directly from your shell.
Zsh automatically quotes your expressions:
The metric system is the tool of the devil! My car gets forty rods to the hogshead, and that's the way I like it! ― Grampa Simpson, A Star Is Burns
Storing unquoted history
As is, Zsh records the quoted expression in history. You must unquote it
before submitting it again. Otherwise, the ZLE widget quotes it a second time.
Bart Schaefer provided a solution to store the
original version:
The zshaddhistory hook returns 1 if we are evaluating an expression, telling
Zsh not to record the command. The preexec hook then adds the original,
unquoted command with print -s.
The complete code is available in my zshrc. A common alternative is the
noglob precommand modifier. If you stick with to instead of ->
for unit conversion, it covers 90% of use cases. For a related Zsh line editor
trick, see how I use auto-expanding aliases to fix common typos.
This is the fastest a packet can travel back and forth between
Paris and Marseille over optical fiber. ↩︎
Qalculate is less understanding with units. For example, it parses
“Mbps” as megabarn per picosecond: ☢️
I saw Ladytron perform in Digital, Newcastle last night. The
last time I saw them was, I think, at the same venue, 18 years ago. Time flies!
Back in the day (perhaps their heyday, perhaps not!) Ladytron ploughed a
particular sonic furrow and did it very well. Going into the gig I had set my
expectations that, should they play just these hits, I'd have a good time.
The gig exceeded my expectations. The setlist very much did not lean into
their best-known period: the more recent few albums were very well represented
and to me this felt very confident. The lead singer, Helen Marnie, demonstrated
some excellent range, particularly on some of the new songs. Daniel Hunt did a
lot of backing vocals and they were really complementary to Helen's: underscoring
but not overpowering. I enjoyed nerding out watching Mira Ayoro's excellent
wrangling of her Korg MS-20. One highlight was an encore performance of
Light & Magic, which was arguably the "alternate version" as available on the
expanded versions of that album or the Remixed and Rare companion.
I thought I'd try to put together a 5-track playlist for a friend who attended
the gig but isn't super familiar with them. As usual this is hard. I'm going
to avoid the obvious hits, try to represent their whole career and try to
ensure the current trio each get a vocal turn in the selection.
They actually released their latest album, Paradises, yesterday as well. One
track from it is in the list below.
When you’re looking at source code it can be helpful to have some evidence
indicating who wrote it. Author tags give a surface level indication, but
it turns out you can just
lie
and if someone isn’t paying attention when merging stuff there’s certainly a
risk that a commit could be merged with an author field that doesn’t
represent reality. Account compromise can make this even worse - a PR being
opened by a compromised user is going to be hard to distinguish from the
authentic user. In a world where supply chain security is an increasing
concern, it’s easy to understand why people would want more evidence that
code was actually written by the person it’s attributed to.
git has support for cryptographically signing
commits and tags. Because git is about choice even if Linux isn’t, you can
do this signing with OpenPGP keys, X.509 certificates, or SSH keys. You’re
probably going to be unsurprised about my feelings around OpenPGP and the
web of trust, and X.509 certificates are an absolute nightmare. That leaves
SSH keys, but bare cryptographic keys aren’t terribly helpful in isolation -
you need some way to make a determination about which keys you trust. If
you’re using someting like GitHub you can extract that
information from the set of keys associated with a user account1, but
that means that a compromised GitHub account is now also a way to alter the
set of trusted keys and also when was the last time you audited your keys
and how certain are you that every trusted key there is still 100% under
your control? Surely there’s a better way.
SSH Certificates
And, thankfully, there is. OpenSSH supports
certificates, an SSH public key that’s been signed by some trusted party and
so now you can assert that it’s trustworthy in some form. SSH Certificates
also contain metadata in the form of Principals, a list of identities that
the trusted party included in the certificate. These might simply be
usernames, but they might also provide information about group
membership. There’s also, unsurprisingly, native support in SSH for
forwarding them (using the agent forwarding protocol), so you can keep your
keys on your local system, ssh into your actual dev system, and have access
to them without any additional complexity.
And, wonderfully, you can use them in git! Let’s find out how.
Local config
There’s two main parameters you need to set. First,
1
git config set gpg.format ssh
because unfortunately for historical reasons all the git signing config is
under the gpg namespace even if you’re not using OpenPGP. Yes, this makes
me sad. But you’re also going to need something else. Either
user.signingkey needs to be set to the path of your certificate, or you
need to set gpg.ssh.defaultKeyCommand to a command that will talk to an
SSH agent and find the certificate for you (this can be helpful if it’s
stored on a smartcard or something rather than on disk). Thankfully for you,
I’ve written one. It will
talk to an SSH agent (either whatever’s pointed at by the SSH_AUTH_SOCK
environment variable or with the -agent argument), find a certificate
signed with the key provided with the -ca argument, and then pass that
back to git. Now you can simply pass -S to git commit and various other
commands, and you’ll have a signature.
Validating signatures
This is a bit more annoying. Using native git tooling ends up calling out to
ssh-keygen2, which validates signatures against a file in a format
that looks somewhat like authorized-keys. This lets you add something like:
1
* cert-authority ssh-rsa AAAA…
which will match all principals (the wildcard) and succeed if the signature
is made with a certificate that’s signed by the key following
cert-authority. I recommend you don’t read the code that does this in
git
because I made that mistake myself, but it does work. Unfortunately it
doesn’t provide a lot of granularity around things like “Does the
certificate need to be valid at this specific time” and “Should the user
only be able to modify specific files” and that kind of thing, but also if
you’re using GitHub or GitLab you wouldn’t need to do this at all because
they’ll just do this magically and put a “verified” tag against anything
with a valid signature, right?
Haha. No.
Unfortunately while both GitHub and GitLab support using SSH certificates
for authentication (so a user can’t push to a repo unless they have a
certificate signed by the configured CA), there’s currently no way to say
“Trust all commits with an SSH certificate signed by this CA”. I am unclear
on why. So, I wrote my
own. It takes a range of
commits, and verifies that each one is signed with either a certificate
signed by the key in CA_PUB_KEY or (optionally) an OpenPGP key provided in
ALLOWED_PGP_KEYS. Why OpenPGP? Because even if you sign all of your own
commits with an SSH certificate, anyone using the API or web interface will
end up with their commits signed by an OpenPGP key, and if you want to have
those commits validate you’ll need to handle that.
In any case, this should be easy enough to integrate into whatever CI
pipeline you have. This is currently very much a proof of concept and I
wouldn’t recommend deploying it anywhere, but I am interested in merging
support for additional policy around things like expiry dates or group
membership.
Doing it in hardware
Of course, certificates don’t buy you any additional security if an attacker
is able to steal your private key material - they can steal the certificate
at the same time. This can be avoided on almost all modern hardware by
storing the private key in a separate cryptographic coprocessor - a Trusted
Platform Module on
PCs, or the Secure
Enclave
on Macs. If you’re on a Mac then Secretive has
been around for some time, but things are a little harder on Windows and
Linux - there’s various things you can do with
PKCS#11 but you’ll hate yourself
even more than you’ll hate me for suggesting it in the first place, and
there’s ssh-tpm-agent except
it’s Linux only and quite tied to Linux.
So, obviously, I wrote my
own. This makes use of the
go-attestation library my team
at Google wrote, and is able to generate TPM-backed keys and export them
over the SSH agent protocol. It’s also able to proxy requests back to an
existing agent, so you can just have it take care of your TPM-backed keys
and continue using your existing agent for everything else. In theory it
should also work on Windows3 but this is all in preparation for a
talk I only found out I was giving about two weeks
beforehand, so I haven’t actually had time to test anything other than that
it builds.
And, delightfully, because the agent protocol doesn’t care about where the
keys are actually stored, this still works just fine with forwarding - you
can ssh into a remote system and sign something using a private key that’s
stored in your local TPM or Secure Enclave. Remote use can be as transparent
as local use.
Wait, attestation?
Ah yes you may be wondering why I’m using go-attestation and why the term
“attestation” is in my agent’s name. It’s because when I’m generating the
key I’m also generating all the artifacts required to prove that the key was
generated on a particular TPM. I haven’t actually implemented the other end
of that yet, but if implemented this would allow you to verify that a key
was generated in hardware before you issue it with an SSH certificate - and
in an age of agentic bots accidentally exfiltrating whatever they find on
disk, that gives you a lot more confidence that a commit was signed on
hardware you own.
Conclusion
Using SSH certificates for git commit signing is great - the tooling is a
bit rough but otherwise they’re basically better than every other
alternative, and also if you already have infrastructure for issuing SSH
certificates then you can just reuse it4 and everyone wins.
Did you know you can just download people’s SSH pubkeys from github from https://github.com/<username>.keys? Now you do ↩︎
Yes it is somewhat confusing that the keygen command does things
other than generate keys ↩︎
Continuing from the last post, Badri and I took a flight from the Brunei International Airport to Kuala Lumpur on the 12th of December 2024. We reached Kuala Lumpur in the evening.
After arriving at the airport, we went through immigration. In a previous post, I mentioned that we had put our stuff in lockers at the TBS bus terminal in Kuala Lumpur. Therefore, we had to go there.
The locker was automated and required us to enter the PIN we had set. Upon entering the PIN, the locker wasn’t getting unlocked. After trying this for 10-15 minutes without any luck, we tried getting some help as there the lockers weren’t under supervision.
So, I roamed around and found a staff member, reporting that our lockers weren’t getting unlocked. They called the person who was in-charge of the lockers. He came to us in a few minutes and used their admin access to open the locker. We were supposed to pay for using the lockers by putting the banknotes inside through a slot. However, as the machine wasn’t working, we gave the amount for the use of our locker service to that person instead.
We soon went back to the KL airport to catch our morning flight to Ho Chi Minh City in Vietnam. At the flight counter, we were afraid we would have to pay extra as our luggage surpassed the allowed weight limit. This one was also a budget airline—AirAsia—and our tickets didn’t include a check-in bag.
Generally, passengers from countries requiring a visa to visit Vietnam (such as India) require going to the airline and showing their visa to get the boarding pass. However, when we went to the AirAsia counter at the Kuala Lumpur airport, they didn’t weigh our bags and asked us to get our boarding passes from an automated kiosk. So, we got our boarding passes printed and proceeded to the airport security.
While clearing the airport security, a lotion I bought from Singapore was confiscated because it was 200 mL, exceeding the limit of 100 mL per bottle. Had that 200 mL liquid been in two different bottles of 100 mL each, I would have been allowed to take it in my carry-on bag, but a single 200 mL bottle wasn’t! I was allowed to keep it in the check-in bag, but I didn’t have it included in my ticket. Huh, airports and their weird rules :( The lotion was an expensive one, so having it thrown away did ruin my mood.
Overview
We started our Vietnam trip from Ho Chi Minh City in the south on the 13th of December 2024 and finished it in Hanoi in the north on the 20th of December. We traveled from Ho Chi Minh City to Hanoi mostly by train, except for a hundred or so kilometers by bus, in chunks. On the way, we visited Nha Trang, Hoi An, and Hue. The distance between Ho Chi Minh City and Hanoi is 1700 km.
For your reference, here are those places labeled on Vietnam’s map.
We landed in Ho Chi Minh City early morning on the 13th of December 2024. I was tired and sleepy as I hadn’t gotten a good night’s sleep. After going through immigration, we went to a currency exchange counter to get Vietnamese Dong. Unlike other countries on this trip, money exchange counters in Vietnam didn’t accept Indian rupees. Therefore, we exchanged euros to get Vietnamese dong at the airport.
After getting out of the airport, we took a bus to the city center. It was 15,000 dongs—approximately 50 Indian rupees. Our plan was to meet Badri’s friend and stay the night at his apartment.
So we went to a café nearby and bought a coffee for each of us for 75,000 dongs. We went upstairs and sat for a while. The Wi-Fi password was mentioned on our bill. During the trip, I found out about the café culture of Vietnam. They have their own coffee brands (such as Highlands Coffee), and you can sit down at any of the cafés for work or wait for the rain to stop. It rained a lot while we were there, so we did use these cafés for that purpose.
Badri’s friend met us there, and we roamed around the area a bit, which included roaming inside a beautiful park. Then Badri’s friend took us to a restaurant. Because I do not eat meat, he took us to a vegan restaurant. Having been to four Southeast Asian countries at this point (excluding Vietnam), I was under the impression that there wouldn’t be a lot of things for my diet in Vietnam.
A picture of the park we roamed around in Ho Chi Minh City. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
However, I was pleasantly surprised at the restaurant. I found all the dishes to be tasty, especially their signature noodles called Pho. I liked another dish so much that I tracked down the restaurant again with Badri using the geotagged image of the bill I had taken earler to have it again. As a tip for vegans coming to Vietnam, the places having the letters “Chay” (without any accented letters) in their name are vegan only.
This is the restaurant Badri’s friend took us to. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
One of the dishes we had in the restaurant. This one was especially tasty. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
One of the dishes we had in the restaurant. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
These noodles are called Pho and are very popular in Vietnam. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
In the night, we went to a supermarket where I got myself some oranges and guavas. Then, we went to a Japanese restaurant where I didn’t have anything, as there was no vegetarian option available for me. Then we took a free bus to the place to Badri’s friend’s apartment. The construction company that built the apartment also runs this free bus service from their residential area to different parts of the city as a way of promoting their apartments. Anyone can take the bus, not just residents.
The next day, we took the free bus back to the city center and checked in to a hostel for a night. We took two beds in dormitories, which were 88,000 dongs (270 rupees) for each bed for a night. In Vietnam, if you can spend around 300 rupees per night, you can get a bed in a decent hostel.
Train from Ho Chi Minh City to Nha Trang
On the night of the 15th of December 2024, we boarded a train from Ho Chi Minh City to Nha Trang. The ticket for each of us was 519,000 dongs (1600 Indian rupees). The train name was SNT2. When we reached the Ho Chi Minh City train station, we noticed that the station was rather small by Indian standards.
After entering the train station, we went inside to the first platform, where the tickets were checked by a staff member. Ho Chi Minh City was the originating station for our train, so our train was already standing at the station. We had to cross the railway tracks on foot to reach the platform our train was on. Then we located our coach, where a ticket inspector was standing at the gate. He let us in after checking our tickets. In all these instances, we just had to show our digital boarding pass which we had received by email.
Unlike Indian trains, the train didn’t have side berths. Additionally, I liked the fact that it had a dedicated space to put our bags in, which was very convenient. The train departed from Ho Chi Minh City at 21:05 and arrived in Nha Trang at 05:30 in the morning.
Interior of our train coach. Trains in Vietnam don’t have side berths, unlike India. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
A picture of the berths from our coach. It had three tiers, similar to a 3 AC coach in Indian trains. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
The train had a cabin to put the bags in. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Nha Trang train station. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Nha Trang
Nha Trang is a coastal place, and we planned to go to a beach. We figured out that the bus to the airport goes can drop us near the beach. Therefore, we went to the bus station to get to the airport bus. The bus station was walking distance from the railway station. So, we decided to walk.
On the way, we stopped at a small shop for a coffee. The shop also gave a complimentary cup of green tea along with the coffee. I found out later that it is common for local shops to give a cup of complimentary green tea in Vietnam.
I got a complimentary cup of green tea along with coffee in Nha Trang. In this trip, Badri and I found out that this is customary at local places in Vietnam. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Soon we reached the bus station and took a bus to the beach. It was 65,000 dongs (₹200). After getting down from the bus, I had coconut water and some eggs at a small local place.
Eggs being cooked on a pan for my order. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Then we went to the beach, but nobody else was there. We spent some time there and went back to the place where the bus dropped us as it started raining. We couldn’t find a bus for some time. A taxi driver approached us and agreed to take us to the city center for 200,000 dongs (₹650). For reference, the place where he dropped us was 35 km from the place we took the taxi. Taxi fares in Vietnam were also cheap!
The beach we went to in Nha Trang. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Nha Trang was a beautiful place, and so we roamed around for a while. Then we stopped at a Highlands Coffee branch for a while. Since Christmas was coming up, the café had a Christmas tree, and I liked the Christmas vibes. They were playing Mariah Carey’s All I Want for Christmas Is You.
This one was shot in the city center. In this trip, Badri and I found out that this is customary at local places in Vietnam. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Inside a Highlands Coffee cafe in Nha Trang. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
A coffee I got from Highlands Coffee in Nha Trang. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
During the evening, we went to a local place to eat. The place mentioned “Chay” in its name, and you know what it means—it was a vegan place. There was a man there and no other customers. I don’t remember the names of the dishes we ordered, but it was a bowl of soupy noodles and a bowl of dry noodles. They were very tasty. To top that off, the meal was a total of 55,000 dongs (₹180) for both of us.
The host was welcoming and friendly. We had a nice conversation with the host. In Vietnam, restaurants give chopsticks to eat noodles. While Badri was good at using them, I wasn’t. So, the host of this restaurant helped me in using chopsticks. Although my technique was not perfect and I take a bit of time, I could now eat solely with chopsticks.
The restaurant we went to in Nha Trang. The word Chay in the name means it was a vegan restaurant. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Soupy noodles we got at that restaurant. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Dry noodles we got at that restaurant. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Our plan was to take a night bus to Hoi An, and we were hoping to find a bus stand. However, we couldn’t find one. Asking around about the pickup location of the Hoi An bus led us to many different locations. Finally, we ended up at a bus booking agency’s office where we found out that there were no tickets available for Hoi An.
At this point, we gave up on booking the bus and searched for trains instead. As we didn’t have a local SIM, we asked the agency to let us connect to their Wi-Fi so that we could look for trains. They were kind enough to let us do that. It also seemed like they were going to close the office in like 10 minutes.
Unfortunately, all the sleeper berths were booked from Nha Trang till Hoi An on the next train with only seating berths being available. It takes around 10 hours, so I wasn’t comfortable traveling on seating berths.
Here I came up with the idea to look for sleeper berths from an intermediate stop. Fortunately, there were sleeper berths available from the next stop, Ninh Hòa. Therefore, we booked a seating berth from Nha Trang to Ninh Hòa and a sleeper berth from Ninh Hòa to Trà Kiệu (the nearest railway station from Hoi An). The train name was SE6, and it was a total of 500,000 dongs per person (₹1600 per person).
So, we went to the Nha Trang railway station and boarded the train. We had to spend 40 minutes seated for the train to reach the next stop before we could go to our sleeper berths. Badri had some friendly co-passengers on that trip who gave him Saigon beer and some crispy papad-like thing. They offered me as well, but I thought it was non-veg, so I declined it.
Hoi An
On the morning of 17th December 2024, we got down at the Trà Kiệu station at around 09:30. Our hostel was in Hoi An, which was around 22 km from the station. There was no public transport to get there.
Instead, there was a taxi driver at the train platform. We told him the name of our hostel, and he quoted 270,000 dongs (around ₹850). We said it was too expensive for us, so he agreed to bargain at 250,000 dongs. At this point, we told him that we could give him no more than 200,000 dongs, but he didn’t agree.
Badri tried a trick. He asked the driver to show us prices in the Grab app (a popular taxi booking app in Southeast Asia). Unfortunately, the Grab app showed 258,000 dongs, which was more than the fare the driver agreed to.
So we walked away as if we had so many options (we didn’t!) to reach the hostel. We got out of the station and stopped at a small shop outside to have some coffee. As is customary in Vietnam, we got a complimentary green tea here as well.
This was the place we had our coffee in Tra Kieu. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
That taxi driver also joined us and sat in that shop. He started talking with the locals in the shop in the local language. The taxi driver was insistent on taking us to Hoi An for 250,000 dongs. At this point, Badri told the taxi driver (by the use of translation software) that we usually use public transport during our trips, and we aren’t used to paying high prices to get around. So, he can drop us somewhere in Hoi An for 200,000 dongs as we don’t mind walking a bit to reach our hotel.
After reading this, the taxi driver agreed to take us to our hostel for 200,000 dongs (₹660). He also had me take a picture with Badri after this. I think such a bargain tactic would not work in India.
Photo of Badri with taxi driver. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
The nice thing we noticed in Vietnam is, once bargaining is done and the deal is settled, people don’t try to bargain more or keep on talking about the subject. Before the deal, the driver was being somewhat insistent and argumentative, but after the deal was done, it was as if no argument had happened at all.
A picture of Tra Kieu area near the train station we got down at. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
We were treated to some beautiful scenery on the way to our hostel. Soon we reached our place and completed all the formalities for checking-in. During the time our room was being prepared for check-in, we had an egg sandwich with coffee in the hotel. I found the egg sandwich very tasty. The bread looked like the French baguette. The hostel was ₹240 per night for each of us.
The name of the hostel was Bana Spa. We liked staying here and we can recommend it if you find yourself there. It is operated by a family.
Our breakfast in Hoi An. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
A photo of the hostel we stayed in Hoi An. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
We also rented a bicycle for each of us—25,000 dongs per day (₹80)—and explored the old town during the evening. Hoi An is popular for Vietnamese silk. Tourists come here to buy fabric and get it done by the tailor. The buildings here looked old, and they were painted in yellow with a gabled roof.
Typical yellow house with gabled roof in Hoi An old town. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Here, I also had egg coffee for the first time, and I liked it. Egg coffee is a delicacy of Hanoi, but you can get it in other parts of Vietnam. If you find yourself in Vietnam, then I recommend you try egg coffee. We also bought some cool T-shirts and other souvenirs, such as a Vietnamese hat, from here.
Egg coffee I had in Hoi An. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Hue
The next day—the 18th of December 2024—we went to Hue by bus. As we could not take a bus on our own in Nha Trang, we asked the hostel to book it for us this time. We booked it a day before, and they told us to be ready by 07:00 in the morning. At 07:00, a minibus arrived, which took us to a bus agency’s office. There we waited for a few minutes and got into the bus to Hue.
The bus had sleeper seats, so I took the opportunity to catch some sleep. The ride was comfortable, so I am assuming the roads were good. In a couple of hours, we reached Hue. Again, we went to Highlands Coffee to have some coffee, charge our phones, and use the internet, not to mention using the bathrooms.
During the afternoon, we went to a local restaurant named Quán Chay Thanh Liễu. It was a vegan restaurant (remember the thing I mentioned earlier about “Chay” being in the name?). On the way, we had a steamed dumpling shaped like a momo called banh bao from a street vendor. It wasn’t very good, but I found it worthwhile.
Bahn Bao in Hue. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
At the restaurant, we ordered a hot pot. First, they brought noodles and a gas stove. Then came the stock and our gas stove was turned on. The stock was kept simmering on the stove. Then, we had it bit by bit with the noodles. A big hot pot at this place costs 50,000 dongs (₹170). Then we had bánh cuốn. These were steamed rolls made of rice flour for 10,000 dongs (₹33).
Hot Pot. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Added soup to the noodles. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Steamed rolls made of rice flour. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Restaurants in Vietnam usually add photos of the meals in their menu or write a description in English. So, even though the dish names were Vietnamese, we had no problems in ordering food there. In addition, all the places we went to provided free Wi-Fi. They either mention the Wi-Fi password on the bill, on the menu or paste it on the wall. This made our trip smoother without getting a local SIM.
Menu from a restaurant in Ho Chi Minh City with detailed description of the food. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Then we slowly walked towards the railway station, as we had a night train to Hanoi. We had egg coffee in a cafe. Near the railway station, we had a bánh mì (egg sandwich). As for sightseeing, we had plans to visit a couple of places in Hue, but we ended up spending all our time inside sheltered spaces due to heavy rain.
We had booked the train SE20 for Hanoi, which had a departure time of 20:41 from Hue. This one was 948,000 dongs (₹3100) for myself and 870,000 dongs (₹2900) for Badri. My ticket was pricier than Badri’s because I got a lower berth. Our train was late by half an hour, so we waited in the common area of the station. After the train arrived, we got inside and took our seats.
The cabin had four berths—two upper and two lower, similar to India’s First AC class. The ticket inspector came to us and offered us the whole cabin (two additional berths) for 300,000 dongs (₹1,000), which we declined. However, this hinted at the other two seats not being reserved. Eventually, we had the whole cabin to ourselves, as nobody else showed up for the other two berths. It was a 14-hour journey, and I got a good sleep.
Our berths in the train. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Hanoi
On the morning of the 19th of December 2024, we reached Vietnam’s capital, Hanoi. We had booked a private hotel room for ₹800. It was 1 km from the Hanoi Airport. However, it was pretty far from the railway station. So, we roamed around in the city and went to the hotel in the evening.
First, we walked to a place and had egg coffee with egg sandwiches. Then we went to Hanoi Train Street, which was walking distance from the train station. After clicking some pictures at the train street, we went to a museum nearby. Upon reaching there, we found out that it was closed.
Egg coffee in Hanoi. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Hanoi train street is a tourist attraction in Hanoi. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Then we went shopping for jackets, as Hanoi was cold compared to other parts of Vietnam we had been to, and since many of them are manufactured in Vietnam, we thought they would be cheaper. I liked some jackets, but they were not my size. Eventually, we didn’t buy anything at the clothes shop.
In the evening, I bought a Vietnamese-styled phin coffee filter and coffee powder from Highlands Coffee. We spent a lot of time in their cafes, so it made sense to buy some souvenirs from there. Badri bought a few coffee filters for his family at Trung Nguyen, where I also bought another filter.
We had dinner at a local place where we had pho and banh it. Bahn it was served packed in banana leaves and it was made of sticky rice.
A picture of pho we had in Hanoi. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Bahn it is served packed in banana leaves. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Bahn it. Photo by Ravi Dwivedi, released under CC-BY-SA 4.0.
Next, we went to Hanoi railway station to catch a bus to the airport since our hotel was 1 km from the airport. The locals there helped us take the bus. It took like an hour to get to the airport. We saw on OpenStreetMap that we can take a bus from there to the hotel, but we could not find it. So we walked to our hotel instead.
It was a decent hotel room for ₹800 for a night. We went outside to explore the area and had egg sandwiches and egg coffee at a local place. Again, we were given a complimentary green tea. We went to this place like three times. We had practically become regulars by the time we left.
The next day— 20th of December 2024 — we took a bus to the airport and boarded our flight to Delhi.
Credits: Thanks Badri, Kishy and Richard for proofreading.
The
WWW::Mechanize::Chrome Saga: A Comprehensive Narrative of PR #104
This document synthesizes the extensive work performed from March
13th to March 20th, 2026, to harden, stabilize, and refactor the WWW::Mechanize::Chrome library and its test suite. This
effort involved deep dives into asynchronous programming,
platform-specific bug hunting, and strategic architectural
decisions.
Part I:
The Quest for Cross-Platform Stability (March 13 – 16)
The initial phase of work focused on achieving a “green” test suite
across a variety of Linux distributions and preparing for a new release.
This involved significant hardening of the library to account for
different browser versions, OS-level security restrictions, and
filesystem differences.
Key Milestones &
Engineering Decisions:
Fedora & RHEL-family Success: A major effort
was undertaken to achieve a 100% pass rate on modern Fedora 43 and
CentOS Stream 10. This required several key engineering decisions to
handle modern browser behavior:
Decision: Implement Asynchronous DOM Serialization
Fallback. Synchronous fallbacks in an async context are
dangerous. To prevent Resource was not cached errors during saveResources, we implemented a fully asynchronous fallback
in _saveResourceTree. By chaining _cached_document with DOM.getOuterHTML
messages, we can reconstruct document content without blocking the event
loop, even if Chromium has evicted the resource from its cache. This
also proved resilient against Fedora’s security policies, which often
block file:// access.
Decision: Truncate Filenames for Cross-Platform
Safety. To avoid File name too long errors,
especially on Windows where the MAX_PATH limit is 260
characters, filenameFromUrl was hardened. The filename
truncation was reduced to a more conservative 150
characters, leaving ample headroom for deeply nested CI
temporary directories. Logic was also added to preserve file extensions
during truncation and to sanitize backslashes from URI paths.
Decision: Expand Browser Discovery Paths. To
support RHEL-based systems out-of-the-box, the default_executable_names was expanded to include headless_shell and search paths were updated to include /usr/lib64/chromium-browser/.
Decision: Mitigate Race Conditions with Stabilization Waits
and Resilient Fetching. On fast systems, DOM.documentUpdated events could invalidate nodeIds immediately after navigation, causing XPath queries
to fail with “Could not find node with given id”. A small stabilization sleep(0.25s) was added after page loads to ensure the DOM
is settled. Furthermore, the asynchronous DOM fetching loop was hardened
to gracefully handle these errors by catching protocol errors and
returning an empty string for any node that was invalidated during
serialization, ensuring the overall process could complete.
Windows Hardening:
Decision: Adopt Platform-Aware Watchdogs. The test
suite’s reliance on ualarm was a blocker for Windows, where
it is not implemented. The t::helper::set_watchdog function
was refactored to use standard alarm() (seconds) on Windows
and ualarm (microseconds) on Unix-like systems, enabling
consistent test-level timeout enforcement.
Version 0.77 Release:
Decision: Adopt SOP for Version Synchronization.
The project maintains duplicate version strings across 24+ files. A
Standard Operating Procedure was adopted to use a batch-replacement tool
to update all sub-modules in lib/ and to always run make clean and perl Makefile.PL to ensure META.json and META.yml reflect the new
version. After achieving stability on Linux, the project version was
bumped to 0.77.
Infrastructure & Strategic Work:
The ad2 Windows Server 2025 instance was restored and
optimized, with Active Directory demoted and disk I/O performance
improved.
A strategic proposal for the Heterogeneous Directory
Replication Protocol (HDRP) was drafted and published.
Part II: The
Great Async Refactor (March 17 – 18)
Despite success on Linux, tests on the slow ad2 Windows
host were still plagued by intermittent, indefinite hangs. This
triggered a fundamental architectural shift to move the library’s core
from a mix of synchronous and asynchronous code to a fully non-blocking
internal API.
Key Milestones &
Engineering Decisions:
Decision: Expose a _future API.
Instead of hardcoding timeouts in the library, the core strategy was to
refactor all blocking methods (xpath, field, get, etc.) into thin wrappers around new non-blocking ..._future counterparts. This moved timeout management to
the test harness, allowing for flexible and explicit handling of
stalls.
# Example library implementationsub xpath($self, $query, %options) {return$self->xpath_future($query, %options)->get;}sub xpath_future($self, $query, %options) {# Async implementation using $self->target->send_message(...)}
Decision: Centralize Test Hardening in a Helper.
A dedicated test library, t/lib/t/helper.pm, was created to
contain all stabilization logic. “Safe” wrappers (safe_get, safe_xpath) were implemented there, using Future->wait_any to race asynchronous operations against
a timeout, preventing tests from hanging.
Decision: Refactor Node Attribute Cache.
Investigations into flaky checkbox tests (t/50-tick.t)
revealed that WWW::Mechanize::Chrome::Node was storing
attributes as a flat list ([key, val, key, val]), which was
inefficient for lookups and individual updates. The cache was refactored
to definitively use a HashRef, providing O(1) lookups
and enabling atomic dual-updates where both the browser property (via
JS) and the internal library attribute are synchronized
simultaneously.
Decision: Implement Self-Cancelling Socket
Watchdog. On Windows, traditional watchdog processes often
failed to detect parent termination, leading to 60-second hangs after
successful tests. We implemented a new socket-based watchdog in t::helper that listens on an ephemeral port; the background
process terminates immediately when the parent socket closes,
eliminating these cumulative delays.
Decision: Deep Recursive Refactoring & Form
Selection. To make the API truly non-blocking, the entire
internal call stack had to be refactored. For example, making get_set_value_future non-blocking required first making its
dependency, _field_by_name, asynchronous. This culminated
in refactoring the entire form selection API (form_name, form_id, etc.) to use the new asynchronous _future lookups, which was a key step in mitigating the
Windows deadlocks.
Evaluation Normalization: Implemented a _process_eval_result helper to centralize the parsing of
results from Runtime.evaluate. This ensures consistent
handling of return values and exceptions between synchronous
(eval_in_page) and asynchronous (eval_future)
calls.
Memory Cycle Mitigation: A significant memory
leak was discovered where closures attached to CDP event futures (like
for asynchronous body retrieval) would capture strong references to $self and the $response object, creating a
circular reference. The established rule is to now always use Scalar::Util::weaken on both $self and any
other relevant objects before they are used inside a ->then block that is stored on an object.
Context Propagation (wantarray): A
major regression was discovered where Perl’s wantarray
context, which distinguishes between scalar and list context, was lost
inside asynchronous Future->then blocks. This caused
methods like xpath to return incorrect results (e.g., a
count instead of a list of nodes). The solution was to adopt the “Async
Context Pattern”: capture wantarray in the synchronous
wrapper, pass it as an option to the _future method, and
then use that captured value inside the future’s final resolution
block.
Asynchronous Body Retrieval & Robust Content
Fallbacks: Fixed a bug where decoded_content()
would return empty strings by ensuring it awaited a __body_future. This was implemented by storing the
retrieval future directly on the response object
($response->{__body_future}). To make this more robust,
a tiered strategy was implemented: first try to get the content from the
network response, but if that fails (e.g., for about:blank
or due to cache eviction), fall back to a JavaScript XMLSerializer to get the live DOM content.
Signature Hardening: Fixed “Too few arguments”
errors when using modern Perl signatures with Future->then. Callbacks were updated to use optional
parameters (sub($result = undef) { ... }) to gracefully
handle futures that resolve with no value.
XHTML “Split-Brain” Bug: Resolved a
long-standing Chromium bug (40130141) where content provided via setDocumentContent is parsed differently than content
loaded from a URL. A workaround was implemented: for XHTML documents,
WMC now uses a JavaScript-based XPath evaluation
(document.evaluate) against the live DOM, bypassing the
broken CDP search mechanism.
Derived Architectural Rules
& SOPs:
Rule: Always provide _future variants.
Every library method that interacts with the browser via CDP must have a
non-blocking asynchronous counterpart.
Rule: Centralize stabilization in the test layer.
All timeout and retry logic should reside in the test harness
(t/lib/t/helper.pm), not in the core library.
Rule: Explicitly propagate wantarray
context. Synchronous wrappers must capture the caller’s context
and pass it down the Future chain to ensure correct
scalar/list behavior.
Rule: The entire call chain must be asynchronous.
To enable non-blocking timeouts, even a single “hidden” blocking call in
an otherwise asynchronous method will cause a stall.
SOP: Reduce Library Noise. Diagnostic messages
(warn, note, diag) should be
removed from library code before commits. All such messages should be
converted to use the internal $self->log('debug', ...)
mechanism, ensuring a clean TAP output for CI systems.
Part III: The MutationObserver Saga (March 19)
With most of the library refactored to be asynchronous, one stubborn
test, t/65-is_visible.t, continued to fail with timeouts.
This led to an ambitious, but ultimately unsuccessful, attempt to
replace the wait_until_visible polling logic with a more
“modern” MutationObserver.
Key Milestones & Challenges:
The Theory: The goal was to replace an inefficient repeat { sleep } loop with an event-driven MutationObserver in JavaScript that would notify Perl
immediately when an element’s visibility changed.
Implementation & Cascade Failure: The
implementation proved incredibly difficult and introduced a series of
new, hard-to-diagnose bugs:
An incorrect function signature for callFunctionOn_future.
A critical unit mismatch, passing seconds from Perl to JavaScript’s setTimeout, which expected milliseconds.
A fundamental hang where the MutationObserver’s
JavaScript Promise would never resolve, even after the
underlying DOM element changed.
Debugging Maze: Multiple attempts to fix the checkVisibility JavaScript logic inside the observer
callback, including making it more robust by adding DOM tree traversal
and extensive console.log tracing, failed to resolve the
hang. This highlighted the opacity and difficulty of debugging complex,
cross-language asynchronous interactions, especially when dealing with
low-level browser APIs.
Procedural Learning:
Granular Edits
The effort was plagued by procedural missteps in using automated
file-editing tools. Initial attempts to replace large code blocks in a
single operation led to accidental code loss and match failures.
Decision: Adopt “Delete, then Add” Workflow.
Following forceful user correction, a new SOP was established for all
future modifications:
Isolate: Break the file into small, manageable
chunks (e.g., 250 lines).
Delete: Perform a “delete” operation by replacing
the old code block with an empty string.
Add: Perform an “add” operation by inserting the
new code into the empty space.
Verify: Verifying each atomic step before
proceeding. This granular process, while slower, ensured surgical
precision and regained technical control over the large Chrome.pm module.
The consistent failure of the MutationObserver approach
eventually led to the decision to abandon it in favor of stabilizing the
original, more transparent implementation.
Part IV:
Reversion and Final Stabilization (March 20)
After exhausting all reasonable attempts to fix the MutationObserver, a strategic decision was made to revert
to the simpler, more transparent polling implementation and fix it
correctly. This proved to be the correct path to a stable solution.
Key Milestones &
Engineering Decisions:
Decision: Perform Strategic Reversion. The MutationObserver implementation, when integrated via callFunctionOn_future with awaitPromise,
proved fundamentally unstable. Its JavaScript promise would consistently
fail to resolve, causing indefinite hangs. A decision was made to revert all MutationObserver code from WWW::Mechanize::Chrome.pm and restore the original repeat { sleep } polling mechanism. A stable,
understandable solution was prioritized over an elegant but broken
one.
Decision: Correct Timeout Delegation in the
Harness. The root cause of the original timeout failure was
identified as a race condition in the t/lib/t/helper.pm
test harness. The safe_wait_until_* wrappers were
implementing their own timeout (via wait_any and sleep_future) that raced against the underlying polling
function’s internal timeout. This led to intermittent failures on slow
machines. The helpers were refactored to delegate all timeout
management to the library’s polling functions, ensuring a
single, authoritative timer controlled the operation.
Decision: Optimize Polling Performance. At the
user’s request, the polling interval was reduced from 300ms to 150ms. This modest performance improvement reduced the
test suite’s wallclock execution time by over a second while maintaining
stability.
Decision: Tune Test Watchdogs. The global watchdog
timeout was adjusted to 12 seconds, specifically calculated as 1.5x the
observed real execution time of the optimized test. This provides a
data-driven safety margin for CI.
Part
V: The Last Bug – A Platform-Specific Memory Leak (March 20)
With all other tests passing, a single memory leak failure in t/78-memleak.t persisted, but only on the Windows ad2 environment. This required a different approach than
the timeout fixes.
Key Milestones:
The Bug: A strong reference cycle involving the on_dialog event listener was not being broken on Windows,
despite multiple attempts to fix it. Fixes that worked on Linux (such as
calling on_dialog(undef) in DESTROY) were not
sufficient on the Windows host.
The Diagnosis: The issue was determined to be a
deep, platform-specific interaction between Perl’s garbage collector,
the IO::Async event loop implementation on Windows, and the Test::Memory::Cycle module. The cycle report was identical
on both platforms, but the cleanup behavior was different.
Failed Attempts: A series of increasingly
aggressive fixes were attempted to break the cycle, including:
Moving the on_dialog(undef) call from close() to DESTROY().
Explicitly deleteing the listener and callback
properties from the object hash in DESTROY.
Swapping between $self->remove_listener and $self->target->unlisten in a mistaken attempt to find
the correct un-registration method.
Pragmatic Solution: After exhausting all reasonable
code-level fixes without a resolution on Windows, the user opted to mark
the failing test as a known issue for that specific platform.
Final Fix: The single failing test in t/78-memleak.t was wrapped in a conditional TODO block that only executes on Windows
(if ($^O =~ /MSWin32/i)), formally acknowledging the bug
without blocking the build. This allows the test suite to pass in CI
environments while flagging the issue for future, deeper
investigation.
Part VI: CI Hardening (March
20)
A final failure in the GitHub Actions CI environment revealed one
last configuration flaw.
Key Milestones:
The Bug: The CI was running prove --nocount --jobs 3 -I local/ -bl xt t directly. This
command was missing the crucial -It/lib include path, which
is necessary for test files to locate the t::helper module.
This resulted in nearly all tests failing with Can't locate t/helper.pm in @INC.
The Investigation: An analysis of Makefile.PL revealed a custom MY::test block
specifically designed to inject the -It/lib flag into the make test command. This confirmed that make test is the correct, canonical way to run the test
suite for this project.
The Fix: The .github/workflows/linux.yml file was modified to replace
the direct prove call with make test in the Run Tests step. This ensures the CI environment runs the
tests in the exact same way as a local developer, with all necessary
include paths correctly configured by the project’s build system.
Final Outcome
After this long and arduous journey, the WWW::Mechanize::Chrome test suite is now stable and passing on all targeted platforms, with known
platform-specific issues clearly documented in the code. The project is
in a vastly more robust and reliable state.
This release contains a rebuild RcppExports.cpp to aid
Rcpp in the transition towards
Rcpp::stop() and away from Rf_error() in its
user packages. No othe
The NEWS entry for this release follows.
Changes in
RcppSpdlog version 0.0.28 (2026-03-19)
Regenerate RcppExports.cpp to switch to
(Rf_error) aiding in Rcpp
transition to Rcpp::stop()
I’ve released virtnbdbackup 2.46 which now
attempts to extract the bitlocker recovery keys during backup. The windows
domains need a working qemu agent installed during backup for this to work.
Using the agent, it also extracts the available guestinfo (network config, OS
version etc..) from the domain and stores it alongside with the backup.
Linux kernel security modules provide a good additional layer of security around individual programs by restricting what they are allowed to do, and at best block and detect zero-day security vulnerabilities as soon as anyone tries to exploit them, long before they are widely known and reported. However, the challenge is how to create these security profiles without accidentally also blocking legitimate actions. For MariaDB in Debian and Ubuntu, a new AppArmor profile was recently created by leveraging the extensive test suite with 7000+ tests, giving good confidence that AppArmor is unlikely to yield false positive alerts with it.
AppArmor is a Mandatory Access Control (MAC) system, meaning that each process controlled by AppArmor has a sort of an “allowlist” called profile that defines all capabilities and file paths a program can access. If a program tries to do something not covered by the rules in its AppArmor profile, the action will be denied on the Linux kernel level and a warning logged in the system journal. This additional security layer is valuable because even if a malicious user found a security vulnerability some day in the future, the AppArmor profile severely restricts the ability to exploit it and gain access to the operating system.
AppArmor was originally developed by Novell for use in SUSE Linux, but nowadays the main driver is Canonical and AppArmor is extensively used in Ubuntu and Debian, and many of their derivatives (e.g. Linux Mint, Pop!_OS, Zorin OS) and in Arch. AppArmor’s benefit compared to the main alternative SELinux (used mainly in the RedHat/Fedora ecosystem) is that AppArmor is easier to manage. AppArmor continues to be actively developed, with new major version 5.0 expected to arrive soon.
I also have some personal history contributing some notification handler scripts in Python and I also created the website that AppArmor.net still runs.
Regular review of denials in the system log required
Any system administrator using Debian/Ubuntu needs to know how to check for AppArmor denials. The point of using AppArmor is kind of moot if nobody is checking the denials. When AppArmor blocks an action, it logs the event to the system audit or kernel logs. Understanding these logs is crucial for troubleshooting custom configurations or identifying potential security incidents.
To view recent denials, check /var/log/audit/audit.log or run journalctl -ke --grep=apparmor.
A typical denial entry for MariaDB will look like this (split across multiple lines for legibility):
msg=audit(…): The audit timestamp and event serial number.
apparmor=“DENIED”: Indicates AppArmor blocked the action.
operation: The action being attempted (e.g., open, mknod, file_mmap, file_perm).
profile: The specific AppArmor profile that triggered the denial (in this case the /usr/sbin/mariadbd profile).
name: The file path or resource that was blocked. In the example above, a custom data path was denied access because it wasn’t defined in the profile’s allowed abstractions.
comm: The command name that triggered the denial (here mariadbd).
requested_mask / denied_mask: Shows the permissions requested (e.g., r for read, w for write).
pid: The process ID.
fsuid: The user ID of the process attempting the action.
ouid: The owner user ID of the target file.
If an action seems legit and should not be denied, the sysadmin needs to update the existing rules at /etc/apparmor.d/ or drop a local customization file in at /etc/apparmor.d/local/. If the denied action looks malicious, the sysadmin should start a security investigation and if needed report a suspected zero-day vulnerability to the upstream software vendor (e.g. Ubuntu customers to Canonical, or MariaDB customers to MariaDB).
AppArmor in MariaDB - not a novel thing, and not easy to implement well
Based on old bug reports, there was an AppArmor profile already back in 2011, but it was removed in MariaDB 5.1.56 due to backlash from users running into various issues. A new profile was created in 2015, but kept opt-in only due to the risk of side effects. It likely had very few users and saw minimal maintenance, getting only a handful of updates in the past 10 years.
The primary challenge in using mandatory access control systems with MariaDB lies in the sheer breadth of MariaDB’s operational footprint with diverse storage engines and plugins. Also the code base in MariaDB assumes that system calls to Linux always work – which they do under normal circumstances – and do not handle errors well if AppArmor suddenly denies a system call. MariaDB is also a large and complex piece of software to run and operate, and it can be very challenging for system administrators to root-cause that a misbehavior in their system was due to AppArmor blocking a single syscall.
Ironically, AppArmor is most beneficial exactly due to the same reasons for MariaDB. The larger and more complex a software is, the larger are the odds of a security vulnerability arising between the various components. And AppArmor profile helps reduce this complexity down to a single access list.
Over the years there has been users requesting to get the AppArmor profile back, such as Debian Bug#875890 since 2017. The need was raised recently again by the Ubuntu security team during the MariaDB Ubuntu ‘main’ inclusion review in 2025, which prompted a renewed effort by Debian/Ubuntu developers, mainly myself and Aquila Macedo, with upstream MariaDB assistance from Daniel Black.
A fresh approach: leverage the MariaDB test suite for automated testing and the open source community for reviews
The key to creating a robust AppArmor profile is the ability to know in detail what is expected and normal behavior of the system. One could in theory read all of the source code in MariaDB, but with over two million lines, it is of course not feasible in practice. However, MariaDB does have a very extensive 7000+ test suite, and running it should trigger most code paths in MariaDB. Utilizing the test suite was key in creating the new AppArmor profile for MariaDB: we installed MariaDB on a Ubuntu system, enabled AppArmor in complain mode and iterated on the allowlist by running the full mariadb-test-run with all MariaDB plugins and features enabled until we had a comprehensive yet clean list of rules.
To be extra diligent, we also reworked the autopkgtest for MariaDB in Debian and Ubuntu CI systems to run with the AppArmor profile enabled and to print all AppArmor notices at the end of the run, making it easy to detect now and in the future if the MariaDB test suite triggers any AppArmor denials. If any test fails, the release would not get promoted further, protecting users from regressions.
While developing and triggering manual test runs we used the maximal achievable test suite with 7177 tests. The test is however so extensive it takes over two hours to run, and it also has some brittle tests, so the standard test run in Debian and Ubuntu autopkgtest is limited just to MariaDB’s main suite with about 1000 tests. Having some tests fail while testing the AppArmor profile was not a problem, because we didn’t need all the tests to pass – we merely needed them to run as many code paths as possible to see if they run any system calls not accounted for in the AppArmor profile.
Note that extending the profile was not just mechanical copying of log messages to the profile. For example, even though a couple of tests involve running the dash shell, we decided to not allow it, as it opens too much of a path for a potential exploit to access the operating system.
The result of this effort is a modernized, robust profile that is now production-ready. Those interested in the exact technical details can read the Debian Bug#1130272 and the Merge Request discussions at salsa.debian.org, which hosts the Debian packaging source code.
Now available in Debian unstable, soon Ubuntu – feedback welcome!
Even though the file is just 200 lines long, the work to craft it spanned several weeks. To minimize risk we also did a gradual rollout by releasing the first new profile version in complain mode, so AppArmor only logs would-be-denials without blocking anything. The AppArmor profile was switched to enforce mode only in the very latest MariaDB revision 1:11.8.6-4 in Debian, and a NEWS item issued to help increase user awareness of this change. It is also slated for the upcoming Ubuntu 26.04 “Resolute Raccoon” release next month, providing out-of-the-box hardening for the wider ecosystem.
While automated testing is extensive, it cannot simulate everything. Most notably various complicated replication topologies and all Galera setups are likely not covered. Thus, I am calling on the community to deploy this profile and monitor for any audit denials in the kernel logs. If you encounter unexpected behavior or legitimate denials, please submit a bug report via the Debian Bug Tracking System.
To ensure you are running the latest MariaDB version, run apt install --update --yes mariadb-server. To view the latest profile rules, run cat /etc/apparmor.d/mariadbd and to see if it is enforced review the output of aa-status. To quickly check if there were any AppArmor denials, simply run journalctl -k | grep -i apparmor | grep -i mariadb.
Systemd hardening also adopted as security features keep evolving
For those interested in MariaDB security hardening, note that also new systemd hardening options were rolled out in Debian/Ubuntu recently. Note that Debian and Ubuntu are mainly volunteer-driven open source developer communities, and if you find this topic interesting and you think you have the necessary skills, feel free to submit your improvement ideas as Merge Requests at salsa.debian.org/mariadb-team. If your improvement suggestions are not Debian/Ubuntu specific, please submit them directly to upstream at GitHub.com/MariaDB.
And yet another maintenance release of the tidyCpp
package arrived on CRAN this morning, just days after previous release
which itself came a mere week and a half after its predecessor. It has
been built for r2u as
well. The package offers a clean C++ layer (as well as one small C++
helper class) on top of the C API for R which aims to make use of this
robust (if awkward) C API a little easier and more consistent. See the
vignette for motivating
examples.
This release restores the small CSS file used by the vignette which
we, in a last-second decision, omitted from the previous release. Oddly,
it only failed under the ‘oldrel’ i.e. the R from now nearly two years
ago. But it was still an unenforced error, and this upload corrects
it.
Changes are summarized in the NEWS entry that follows.
Changes in tidyCpp
version 0.0.11 (2026-03-17)
Keep a CSS file in the package to allow vignette build on r-oldrel
too
During the mentorship the mentees acted on several of the team's translation
efforts and joined presentations about the Debian Project and its
community given by the mentors. We thank the dedication and contributions of
Ana Parra, Bruno Freitas, Henrique Barbosa, Raul Banzatto and Vitoria Cordeiro.
And we also thank the members of the team who have reviewed the work of the
mentees, specially the ones who were designated as official mentors, namely
Allythy Rennan, Daniel Lenharo, Thiago Pezzo, and Victor Marinho.
Results:
Package descriptions, translations: 27
Package descriptions, revisions: 190
Web pages: 11
Revisions to the Debian Administrator's Handbook
Revisions to the Debian Edu documentation
We hope that this experience will inspire new paths and that you continue to
contribute to Free Software – especially to Debian.
Wikimedia Nederland organised a new type of event this year, the
Wikimedia Hackathon Northwestern Europe 2026, which was held last
weekend in Arnhem, the Netherlands. And I'm very happy they did,
since unlikelastyears, I will unfortunately be missing from the
"main" Wikimedia Hackathon (which is happening in Milan at the start of
May).
I continue to believe the primary reason for these events existing is
the ability to connect with old and new friends in person. That being
said, I did get a bit of technical tinkering done during the weekend
as well. These include a dark mode fix to MediaWiki's notification
interface, fixes to some visual bugs in MediaWiki's two-factor
authentication and OAuth functionality. I did also get an older
patch of mine about disabling Composer's new auditing functionality
merged. And, as usual, I spent a bunch of time helping various people
use with the various infrastructure pieces I'm familiar with (or at
least had to suddenly get familiar with) and approved a bunch of OAuth
consumers and other requests.
We also managed to continue the tradition from the past two Wikimedia
Hackathons of nominating more people to receive +2 access to
mediawiki/*. That request is still open as of writing, as those have
to run for at least a week, but looks very likely to pass at this
point.
Overall, the event was very well-organized: the venue was great, except
that the number of stairs was described in a rather misleading way,
food was great, and the atmosphere was amazing. The pressure that you
must Just Get Things Done to justify your attendance that the main
hackathon seems to have recently gained was clearly missing here which
was great. Also, I will clearly need to bring more Finnish chocolate
next time.
The timing of Friday and Saturday works great for us with other things
(like university for me) during the week, as it takes full advantage of
the weekend but still only eats workdays from a single calendar week.
My main gripe with the logistics was the focus on a single sketchy
non-free messaging platform for all event-related communications with
the IRC bridge used on the main hackathon channel notably missing.
ps. Like Lucas, I do have Opinions about so many proudly mentioning
they've used "vibe coding" tools during the introduction and showcase.
Those opinions are best left for an another time, but I do want to note
that all of my work and mistakes have still been lovingly handcrafted.
Armadillo is a powerful
and expressive C++ template library for linear algebra and scientific
computing. It aims towards a good balance between speed and ease of use,
has a syntax deliberately close to Matlab, and is useful for algorithm
development directly in C++, or quick conversion of research code into
production environments. RcppArmadillo
integrates this library with the R environment and language–and is
widely used by (currently) 1235 other packages on CRAN, downloaded 44.9 million
times (per the partial logs from the cloud mirrors of CRAN), and the CSDA paper (preprint
/ vignette) by Conrad and myself has been cited 672 times according
to Google Scholar.
This versions updates to the 15.2.4 upstream Armadillo release from
yesterday. The package has already been updated for Debian, and for r2u. This release, which
we as usual checked against the reverse-dependencies, brings minor
changes over the RcppArmadillo release 15.2.3 made in December (and
described here)
by addressing some corner-case ASAN/UBSAN reports (which Conrad, true to his style
of course labels as ‘false positive’ just how he initially
responded that he would ‘never’ add a fix based on such a false report;
as always it is best to just watch what does as he is rather good at it,
and, written comments notwithstanding, quite responsive) as well as
speed-ups for empty sparse matrices. I made one more follow-up
refinement on the OpenMP setup which should now ‘just work’ on all
suitable platforms.
The detailed changes since the last release follow.
Changes in
RcppArmadillo version 15.2.4-1 (2026-03-17)
Upgraded to Armadillo release 15.2.4 (Medium Roast Deluxe)
Workarounds for bugs in GCC and Clang sanitisers (ASAN false
positives)
Another minor maintenance release version 0.1.4 of package RcppClassicExamples
arrived earlier today on CRAN,
and has been built for r2u. This package
illustrates usage of the old and otherwise deprecated initial Rcpp API
which no new projects should use as the normal and current Rcpp API is so much better.
This release, the first in two and half years, mostly aids Rcpp in moving from
Rf_error() to Rcpp::stop() for better
behaviour under error conditions or excections. A few other things were
updated in the interim such as standard upgrade to continuous
integration, use of Authors@R, and switch to static linking and an
improved build to support multiple macOS architectures.
No new code or features. Full details below. And as a reminder, don’t
use the old RcppClassic – use Rcpp
instead.
Changes in version 0.1.4
(2026-03-16)
Continuous integration has been updated several times
DESCRIPTION now uses Authors@R
Static linking is enforced, RcppClassic (>= 0.9.14)
required
Calls to Rf_error() have been replaced with
Rcpp::stop()
Oh dear! I've been suffering print reliability issues on my Prusa
Mini+ for quite a while, roughly since they introduced Input Shaping
(although that might not be the culprit). Whilst trying different
things to resolve it, I managed to sheer off the brass nozzle within
the heatblock. I now have half the nozzle stuck in the ratchet spanner,
and half in the heatblock.
Back in FOSDEM I asked the Prusa folks what cool projects
I could do with the Mini+… they looked a little blank (I think the Mini+
is now a somewhat forgotten product) but they did say somebody had managed
to port over the "Nextruder" from the more recent Prusa XL/MK4. I could
take a look at that.
Another thing I've always wanted to explore (although I had intended it to
be temporary/reversible) was converting it into a plotter, for plotter
art.
Somehow this is my first 3d printing blog post in over a year. The
printables.com feed I linked to is still going,
I'm happy to report (as is the one I wrote but didn't publish, slightly
more surprisingly)
On Friday May the 13th OpenSSL project has published advisory details for CVE-2026-2673. The CVE is treated as non-important by the project. The patches are only provided as commits on the stable branches. No git tag, no precise fixed version, and no source tarballs provided.
The patches that were merged to openssl-3.5 and openssl-3.6 branches were not based on top of the last stable point release and did not split code changes & documentation updates. It means that cherry-picking the commits referenced in the advisory will always lead to conflicts requiring manual resolution. It is not clear if support is provided for snapshot builds off the openssl-3.5 and openssl-3.6 branches. As the builds from the stable branches declare themselves as dev builds of the next unreleased point release. For example, in contrast to projects such as vim and glibc, with every commit to stable branches explicitly recommended for distributors to ship and is supported.
I have requested OpenSSL upstream in the past for the security fixes to branch off the last point release, commit code changes separate from the NEWS.md / CHANGES.md updates, and then merge that into the stable branches. This way the advisory that recommends cherry-picking individual commits, would actually apply conflict free - at no additional maintenance burden to the OpenSSL project and everyone who has to cherry-pick these updates. There is a wide support voiced for such strategy by the OpenSSL distributors and the OpenSSL Corporation. But this is not something that OpenSSL Project is yet choosing to provide.
To avoid duplication of work, I am starting to provide stable OpenSSL re-releases of the last upstream tagged stable point release with security only patches split into code-change only; documentation update; version update to create security only source tarball releases that are easy to build; easy to identify by the security scanners; and which cherry-pick changes without conflicts. The first two releases are published on GitHub as immutable releases with attestations:
If there are any other branches, CVEs, point releases that would be useful for similar style releases, do open discussion on the GitHub Project.
If you find these releases useful, do star the project and download these releases. If this project gets popular, I hope that OpenSSL upstream will reconsider their releases strategy for all security releases. If you have support contracts with OpenSSL - please request OpenSSL corporation to release tagged releases and versioned tarballs.
Debusine is a tool designed for Debian developers and Operating
System developers in general.
Debusine can run QA pipelines to check that Debian packages are ready to
upload.
This blog post describes the regression tracking mechanism that’s
recently become available in Debusine QA pipelines.
The debian_pipeline workflow in Debusine can build, test, and upload
a package to the Debian archive (or any other repository, such as a
native Debusine APT repository).
The QA tests involve running the standard Debian QA utilities
(lintian, autopkgtest, piuparts, blhc) on the built artifacts.
In addition we can run the autopkgtests of every other package in the
archive that depends on the built package, like britney does for testing
migration in Debian.
Some of these other packages may have currently-failing autopkgtests
that have nothing to do with the changes in the upload under test.
For example:
Figuring out which of these failures are new (and thus worth
investigating) has been a manual process in Debusine until now.
We have just completed the basic functionality of the
regression_tracking=true feature, and have enabled it in the
upload-to-* workflows on debusine.debian.net.
With this enabled, you’ll get a new QA tab on your debian_pipeline
workflows that shows the trend of each test:
This is determined by looking at recent task history for each task in
the debian:qa-results collection.
If there is no recent result for a given <package, version,
architecture>, then tasks are queued under the “reference tests”
qa workflow tree on the pipeline.
These reference tests are run by using the same tasks as the main qa
workflow, but without the addition of the package under test.
In fact, it uses the same qa workflow that we use to check the package,
but with a few different parameters to populate the regression tracking
results collection.
The debian:qa-results collection used for analyzing regressions is
specified to the debian_pipeline with the
regression_tracking_qa_results lookup parameter.
On debusine.debian.net we have configured a debian:qa-results
collection for sid that can be referenced and added to by tasks in
any workspace.
Regressions can be more subtle than a simple Success → Failure.
If the number of autopkgtests that fail increases, or the number of
lintian tags emitted increases, those are also considered a regressions.
Using regression tracking now
It’s enabled by default on most of the upload-to-* workflows on
debusine.debian.net.
To disable, pass -O debusine_workflow_data.enable_regression_tracking=false when you dput
an upload to debusine.
To use the regression-tracking in your own workflows, use a
debian_pipeline workflow that is configured with
enable_regression_tracking=true.
This will require a qa_suite to be specified, pointing to the
baseline suite.
We hope this will make it easier to check QA results for packages tested
on debusine.debian.net.
The Debian LTS Team, funded by [Freexian’s Debian LTS offering]
(https://www.freexian.com/lts/debian/), is pleased to report its activities for
February.
Activity summary
During the month of February, 20 contributors have been
paid to work on Debian LTS (links to individual
contributor reports are located below).
We also welcomed Arnaud Rebillout to the team and had to say farewell to Roberto, who left the team after more than nine years as part of it.
The team continued preparing security updates in its usual rhythm. Beyond the
updates targeting Debian 11 (“bullseye”), which is the current release under LTS,
the team also proposed updates for more recent releases (Debian 12 (“bookworm”)
and Debian 13 (“trixie”)), including Debian unstable.
Notable security updates:
Guilhem Moulin prepared DLA 4492-1
for gnutls28 to fix vulnerabilities which may lead to Denial of Service.
Utkarsh Gupta prepared DLA 4464-1
for xrdp, to fix a a vulnerability that could allow remote attackers to execute arbitrary code on the target system.
Emilio Pozuelo Monfort prepared DLA-4465-1
to replace ClamAV 1.0 with ClamAV 1.4. This latter is the current LTS version supported by upstream.
Markus Koschany prepared DLA 4468-1
for tomcat9, to fix a vulnerability that can be used to bypass security constraints.
Santiago Ruano Rincón prepared DLA 4471-1
to update package debian-security-support, the Debian security coverage checker.
Bastien Roucariès prepared DLA 4473-1
for zabbix, to fix a potential remote code execution vulnerability.
Paride Legovini prepared DLA 4478-1
for tcpflow, to fix a vulnerability that might result in DoS and potentially code execution.
Thorsten Alteholz prepared DLA 4477-1
for munge, to fix a vulnerability which may allow local users to leak the MUNGE cryptographic key and forge arbitrary credentials.
Chris Lamb prepared DLA 4482-1
for ceph, to fix SSL certificate checking in the Python bindings.
Andreas Henriksson prepared DLA 4491-1
to fix vulnerabilities in glib2.0, which could result in denial of service, memory corruption or potentially arbitrary code execution.
Contributions from outside the LTS Team:
The update of nova was prepared by the maintainer, Thomas Goirand.
The corresponding DLA 4486-1 was published by Carlos Henrique Lima Melara.
The updates of thunderbird were prepared by the maintainer Christoph Goehre.
The corresponding DLA 4466-1 and DLA 4495-1 was published by Emilio Pozuelo Monfort.
The LTS Team has also contributed with updates to the latest Debian releases:
Jochen prepared a point update of wireshark for bookworm (#1127945).
Jochen prepared point updates of erlang for trixie (#1127606) and bookworm (#1127607).
Bastien helped preparing DSA 6160-1 for netty and uploaded a fixed package to unstable.
Bastien prepared a point update of zabbix for trixie (#1127437).
Tobias prepared a point update of modsecurity-crs for bookworm (#1128655).
Tobias prepared a point update of busybox for bookworm (#1129503).
Daniel prepared point updates of python-authlib for trixie (#1129477) and bookworm (#1129246).
Ben uploaded several Linux kernel packages to trixie-backports and bookworm-backports.
Ben prepared point updates of wireless-regdb for trixie and bookworm.
Other than the work related to updates, Sylvain made several improvements to
the documentation and tooling used by the team.
Some milestones in the lifecycle of two Debian releases are just around the corner.
The support of Debian 12 will be handed over to the LTS team on June 11th 2026.
After August 31st, support for Debian 11 will move from Debian LTS to ELTS managed by Freexian.
On our way to Austria last week, on March 6th, we left my daughter's laptop on a train: ICE 1201 (Hamburg-Harburg to Bludenz).
The laptop is a Lenovo X230 notebook. The most obvious distinguishing feature is a Mathilda Hands sticker in the middle of the lid:
I seem to remember that it also has some hexagonal stickers, one probably being one of these:
The keyboard layout is British (with a £ above the 3).
It was left in coach 24 of ICE 1201, next to seats 51-54, in the luggage gap between the seats, on the floor.
My hope is that whoever found it will end up searching for Mathilda Hands and see this. If that's how you got here, please email me:
phil-lostlaptop2026@hands.com - doing so will make Mathilda (and me) most cheerful.
A maintenance release 0.9.14 of the RcppClassic
package arrived earlier today on CRAN, and has been built for r2u. This package
provides a maintained version of the otherwise deprecated initial Rcpp
API which no new projects should use as the normal and current
Rcpp API is so much better.
A few changes had cumulated up since the last release in late 2022.
We updated continuous integration scripts a few times, switched to
Authors@R in DESCRIPTION, and rejigged build scripts a
little to accommodate both possible build architectures for macOS. We
also updated the vignette by updating all reference and switching the
new asis vignette builder now available in Rcpp.
The Radxa Orion O6 seems to be the
arm64 device I've always wanted. Finally!
Because it supports UEFI boot, Debian can be installed with the vanilla
installation media. Neither custom images, nor additional firmware, nor any
other tricks were required on my end. In fact, the entire process was
indistinguishable from the amd64 installations I've been accustomed to for
two decades: just plug in a USB flash drive, boot, and install.
The system's specs are pretty neat. The CPU is ARMv9.2, though without SME,
which would have been useful for debugging packages that use it in some way.
It's also rich in interfaces, including a Gen4 PCIe x16 slot (with 8 lanes),
which enables me to run tests utilizing GPUs. The BIOS version the board came
with had a bug where WiFi was permanently disabled, but this has been
fixed in the meantime. The only odd thing was the socket for the RTC battery:
the CR1220 it requires seems to be rather niche: none of the hardware stores I
visited carried it, so I had to order one online.
I installed Debian trixie to a
NVMe drive, and for 6 months now, it has been running flawlessly. I've been
using this board as a development and debugging system for arm64 optimizations,
in particular for ggml's feature-specific
arm64 backends which are hard to debug on our porterboxes. However, the host
will soon transition to a general CI worker for AI/ML related packages, similar
to the ROCm CI we've built for testing packages
utilizing AMD GPUs.
I'll post more about this new CI soon.
Purchase of this board was funded by the Debian Project, and was thus enabled
through your donations.
Recently I found myself with a few hours to kill, but with the only
available connectivity provided by an annoying firewall which would
normally allow requests only to a few very specific web sites.
This post shows how to work around this kind of restrictions by hiding
SSH in an HTTPS connection, which then can be used as a SOCKS proxy to
allow general connectivity.
socat
does all the hard work.
First, create two self-signed RSA keys pairs, one for the client
(bongo) and one for the server (attila):
Then, concatenate the public and private keys to create the file
provided to the cert option, and use the public key as
the file for the cafile option on the other
side.
On the client side, if you normally would connect to
attila.example.net then you can add something like this to
~/.ssh/config:
The ProxyCommand directive uses socat to
provide the connectivity which ssh will use over stdio
instead of connecting to port 22 of the server.
The snihost option is enough to make many firewalls
believe that this is an authorized HTTPS request.
On the server side we use a simple systemd unit to start a forking
instance of socat, which will accept and process requests
from the client (and from random crawlers on the Internet: expect a lot
of cruft in that log...):
Strong sandboxing is enabled, so the socat instance
is confined with very limited privileges. An interesting point is the
use of systemd credentials
to provide the cryptographic keys, since it allows to store them in a
part of the file system which would not be accessible to the program.
Advanced users can use this method to provide the keys from secure
storage.
With various forms of IM becoming so prevalent and a lot of communication that used to be via email happening via IM I’ve been thinking about the differences between Email and IM.
I think it’s worth comparing them not for the purpose of convincing people to use one or the other (most people will use whatever is necessary to communicate with the people who are important to them) but for the purpose of considering ways to improve them and use them more effectively.
Also I don’t think that users of various electronic communications systems have had a free choice in what to use for at least 25 years and possibly much longer depending on how you define a free choice. What you use is determined by who you want to communicate with and by what systems are available in your region. So there’s no possibility of an analysis of this issue giving a result of “let’s all change what we use” as almost everyone lacks the ability to make a choice.
What the Difference is Not
The name Instant Messaging implies that it is fast, and probably faster than other options. This isn’t necessarily the case, when using a federated IM system such as Matrix or Jabber there can be delays while the servers communicate with each other.
Email used to be a slow communication method, in the times of UUCP and Fidonet email there could be multiple days of delay in sending email. In recent times it’s expected that email is quite fast, many web sites have options for authenticating an email address which have to be done within 5 minutes so the common expectation seems to be that all email is delivered to the end user in less than 5 minutes.
When an organisation has a mail server on site (which is a common configuration choice for a small company) the mail delivery can be faster than common IM implementations.
The Wikipedia page about Instant Messaging [1] links to the Wikipedia page about Real Time Computing [2] which is incorrect. Most IM systems are obviously designed for minimum average delays at best. For most software it’s not a bad thing to design for the highest performance on average and just let users exercise patience when they get an unusual corner case that takes much longer than expected.
If an IM message takes a few minutes to arrive then “that’s life on the Internet” – which was the catchphrase of an Australian Internet entrepreneur in the 90s that infuriated some of his customers.
Protocol and Data Format Differences
Data Formats
Email data contains the sender, one or more recipients, some other metadata (time, subject, etc), and the message body. The recipients are typically an arbitrary list of addresses which can only be validated by the destination mail servers. The sender addresses weren’t validated in any way and are now only minimally validated as part of anti-spam measures.
IM data is sent through predefined connections called rooms or channels. When an IM message is sent to a room it can tag one or more members of the room to indicate that they may receive a special notification of the message.
In many implementations it’s possible to tag a user who isn’t in the room which may result in them being invited to the room. But in IM there is no possibility to add a user to the CC list for part of a discussion and then just stop CCing messages to them later on in the discussion.
Protocols
Internet email is a well established system with an extensive user base. Adding new mandatory features to the protocols isn’t viable because many old systems won’t be updated any time soon. So while it is possible to send mail that’s SSL encrypted and has a variety of authentication mechanisms that isn’t something that can be mandatory for all email. Most mail servers are configured to use the SSL option if it’s available but send in cleartext otherwise, so a hostile party could launch a Man In the Middle (MITM) attack and pretend to be the mail server in question but without SSL support.
Modern IM protocols tend to be based on encryption, even XMPP (Jabber) which is quite an old IM protocol can easily be configured to only support encrypted messaging and it’s reasonable to expect that all other servers that will talk to you will at least support SSL. Even for an IM system that is run by a single company the fact that communication with the servers is encrypted by SSL makes it safer than most email. A security model of “this can only be read by you, me, and the staff at an American corporation” isn’t the worst type of Internet security.
The Internet mail infrastructure makes no attempt to send mail in order and the design of the Simple Mail Transfer Protocol (SMTP) means that a network problem after a message has been sent but before the recipient has confirmed receipt will mean that the message is duplicated and this is not considered to be a problem.
The IM protocols are designed to support reliable ordered transfer of messages and Matrix (the most recently designed IM protocol) has cryptographic connections between users.
Forgery
For most email systems there is no common implementation that prevents forging email. For Internet email transferred via SMTP it’s possible to use technologies like SPF and DKIM/DMARC to make recipients aware of attempts at forgery, but many recipient systems will still allow email that fails such checks to be delivered. The default configuration tends to be permitting everything and all of the measures to prevent forgery require extra configuration work and often trade-offs as some users desire features that go against security. The default configuration of most mail servers doesn’t even prevent trivial forgeries of email from the domain(s) owned by that server.
For evidence check the SPF records of some domains that you communicate with and see if they end with “-all” (to block email from bad sources), “~all” (to allow email from bad sources through after possibly logging an error), “?all” (to be “neutral” on mail from unknown sources, or just lack a SPF record entirely. The below shows that of the the top four mail servers in the world only outlook.com has a policy to reject mail from bad sources.
In most IM systems there is a strong connection between people who communicate. If I send you two direct messages they will appear in the same room, and if someone else tries forging messages from me (EG by replacing the ‘c’ and ‘e’ letters in my address with Cyrillic letters that look like them or by mis-spelling my name) a separate room will be created and it will be obvious that something unexpected is happening. Protecting against the same attacks in email requires the user carefully reading the message, given that it’s not uncommon for someone to start a message to me with “Hi Russel” (being unable to correctly copy my name from the To: field of the message they are writing) it’s obvious that any security measure relying on such careful reading will fail.
The IM protections against casual forgery also apply to rooms with multiple users, a new user can join a room for the purpose of spamming but they can’t send a casual message impersonating a member of the room. A user can join a Matrix room I’m in with the name “Russell” from another server but the potential for confusion will be minimised by a message notifying everyone that another Russell has joined the room and the list of users will show two Russells. For email the protections against forgery when sending to a list server are no different than those when sending to an individual directly – which means very weak protections.
Authenticating the conversation context once as done with IM is easier and more reliable than authenticating each message independently.
Is Email Sucking the Main Technical Difference?
It seems that the problems with forgery, spam, and general confusion when using email are a large part of the difference between email and IM.
But in terms of technical issues the fact that email has significantly more users (if only because you need an email account to sign up for an IM system) is a major difference.
Internet email is currently a universal system (apart from when it breaks from spam) and it has historically been used to gateway to other email systems like Fidonet, Uucp, and others. The lack of tight connection between parties that exchange messages in email makes it easier to bridge between protocols but harder to authenticate communication.
Most of the problems with Internet email are not problems for everyone at all times, they are technical trade-offs that work well for some situations and for some times. Unfortunately many of those trade-offs are for things that worked well 25+ years ago.
The GUI
From a user perspective there doesn’t have to be a great difference between email and IM. Email is usually delivered quickly enough to be in the same range as IM. The differences in layout between IM client software and email client software is cosmetic, someone could write an email client that organises messages in the same way as Slack or another popular IM system such that the less technical users wouldn’t necessarily know the difference.
The significant difference in the GUI for email and IM software was a design choice.
Conversation Organisation
The most significant difference in the operation of email and IM at the transport level is the establishment of connections in IM. Another difference is the fact that there are no standards implemented for the common IM implementations to interoperate which is an issue of big corporations creating IM systems and deliberately making them incompatible.
The methods for managing email need to be improved. Having an “inbox” that’s an unsorted mess of mail isn’t useful if you want to track one discussion, breaking it out into different sub folders for common senders (similar to IM folders for DMs) as a standard feature without having to setup rules for each sender would be nice. Someone could design an email program with multiple layouts, one being the traditional form (which seems to be copied from Eudora [3]) and one with the inbox (or other folders) split up into conversations. There are email clients that support managing email threads which can be handy in some situations but often isn’t the best option for quickly responding to messages that arrived recently.
Archiving
Most IM systems have no method for selectively archiving messages, there’s a request open for a bookmark function in Matrix and there’s nothing stopping a user from manually copying a message. But there’s nothing like the convenient ability to move email to an archive folder in most IM systems.
Without good archiving IM is a transient medium. This is OK for conversations but not good for determining the solutions to technical problems unless there is a Wiki or other result which can be used without relying on archives.
Composing Messages
In a modern email client when sending a message it prompts you for things that it considers complete, so if you don’t enter a Subject or have the word “attached” in the message body but no file is attached to the message then it will prompt you to confirm that you aren’t making a mistake. In an IM client the default is usually that pressing ENTER sends the message so every paragraph is a new message. IM clients are programmed to encourage lots of short messages while email clients are programmed to encourage more complete messages.
Social Issues
Quality
The way people think about IM and email is very different, as one example there was never a need for a site like nohello.net for email.
The idea that it’s acceptable to use even lower quality writing in IM than people tend to use in email seems to be a major difference between the communication systems.
It can be a good thing to have a chatty environment with messages that are regarded as transient for socialising, but that doesn’t seem ideal for business use.
Ownership
Email is generally regarded as being comparable to physical letters. It is illegal and widely considered to be socially wrong to steal a letter from someone’s letterbox if you regret sending it. In email the only unsend function I’m aware of is that in Microsoft software which is documented to only work within the same organisation, and that only works if the recipient hasn’t read the message. The message is considered to be owned by the recipient.
But for IM it’s a widely supported and socially acceptable function to delete or edit messages that have been sent. The message is regarded as permanently the property of the sender.
What Should We Do?
Community Creators
When creating a community (and I use this in the broadest sense including companies) you should consider what types of communication will work well.
When I started the Flounder group [4] I made a deliberate decision that non-free communication systems go against the aim of the group, I started it with a mailing list and then created a Matrix room which became very popular. Now the list hardly gets any use. It seems that most of the communication in the group is fairly informal and works better with IM.
Does it make sense to use both?
Should IM systems be supplemented with other systems that facilitate more detail such as a Wiki or a Lemmy room/instance [5] to cover the lack of long form communication? I have created a Lemmy room for Flounder but it hasn’t got much interest so far.
It seems that almost no-one makes a strategic decision about such issues.
Software Developers
It would be good to have the same options for archiving IM as there are for email. Also some options to encourage quality in IM communication similar to the way email clients want confirmation before sending messages without a subject or that might be missing an attachment.
It would also be good to have better options for managing conversations in email. The Inbox as currently used is good for some things but a button to switch between that and a conversation view would be good. There are email clients that allow selecting message sort order and aggregation (kmail has a good selection of options) but they are designed for choosing a single setup that you like not between multiple views based on the task you are doing.
It would be good to have links between different communication systems, if users had the option of putting their email address in their IM profile it would make things much easier. Having entirely separate systems for email and IM isn’t good for users.
Users
The overall communications infrastructure could be improved if more people made tactical decisions about where and how to communicate. Keep the long messages to email and the chatty things to IM. Also for IM just do the communication not start with “hello”. To discourage wasting time I generally don’t reply to messages that just say “hello” unless it’s the first ever IM from someone.
Conclusion
A large part of the inefficiencies in electronic communication are due to platforms and usage patterns evolving with little strategic thought. The only apparent strategic thought is coming from corporations that provide IM services and have customer lock in at the core of their strategies.
Free software developers have done great work in developing software to solve tactical problems but the strategies of large scale communications aren’t being addressed.
Email is loosely coupled and universal while IM is tightly coupled, authenticated, and often siloed. This makes email a good option for initial contact but a risk for ongoing discussions.
There is no great solution to these issues as they are largely a problem due to the installed user base. But I think we can mitigate things with some GUI design changes and strategic planning of communication.
What led to this experiment? Well, for one, Well, for one, there was a thought
shared by Andrej Karpathy regarding the shift towards "Agentic" workflows.
"The future of software is not just 'tools', but 'agents' that can navigate
complex tasks on your behalf."
Recently, I spoke with Ritesh, who mentioned his
success using the Gemini CLI to debug an idle power drain issue on his laptop. I
wanted to experiment with this myself, and I had the perfect use case:
configuring the Hyprland Window Manager on my aging laptop.
The machine is nearly eight years old with 12GB of RAM (upgraded from the
original 4GB). I found that GNOME and KDE were becoming overkill, often leading
to system freezes when running multiple AI-powered IDEs like Antigravity and VS
Code with Co-pilot. Coincidentally, I noticed my Jio number had a "Google One
2TB" and "Google AI Premium" plan available to claim. I claimed it, and now here
I am, experimenting with the Gemini CLI.
Getting Started
First, you need to install geminicli. It is an open-source project, and
currently, the easiest way to install it is via the Node Package Manager (npm):
npminstall-g@google/gemini-cli
Next, we need to create a context for Gemini—a set of instructions for it to
follow throughout the project. This is managed via a GEMINI.md file. I went
to Google Gemini, explained my requirements, and asked it to generate one for
me.
My requirements were:
A minimalist but fully functional session, comparable to my existing GNOME
setup.
Basic functionalities including wallpaper, screen locks, and a status bar
with system icons.
Swapping Control and Caps Lock (a must for Emacs users).
Mandatory permission prompts for privileged operations; otherwise, it can
work freely within a specified directory.
Persistent memory/artifacts for the session.
Permission to inspect my current session to understand the existing hardware
and software configuration.
The goal was to reduce bloat and reclaim memory for heavy applications like
Antigravity and VS Code. Gemini provided the following GEMINI.md file:
# Role: Hyprland Configuration Specialist (Minimalist & High-Performance)
You are a Linux Systems Engineer specializing in migrating users from heavy
Desktop Environments to minimalist, tiling-based Wayland sessions on Debian.
Your goal is to maximize available RAM for heavy applications while maintaining
essential desktop features.
## 1. Environment & Persona-**Target OS:** Debian (Linux)
-**Target WM:** Hyprland
-**Hardware:** ThinkPad E470 (i5-7th Gen, 12GB RAM)
-**User Profile:** Emacs user, prioritizes "anti-gravity" (zero bloat).
-**Tone:** Technical, concise, and security-conscious.
## 2. Core Functional Requirements-**Status Bar:**`waybar` (with CPU, RAM, Network, and Battery icons).
-**Wallpaper:**`swww` or `hyprpaper`.
-**Screen Lock:**`hyprlock` + `hypridle`.
-**Input Mapping:** Swap Control and Caps Lock (`kb_options = ctrl:nocaps`).
## 3. Operational Constraints-**Permission First:** Ask before using `sudo` or writing outside the work directory.
-**Inspection:** Use `hyprctl`, `lsmod`, or `gsettings` for compatibility checks.
-**Artifact Management:** Update `MEMORY.md` after every major step.
Gemini also recommended creating a MEMORY.md file to track progress.
Interestingly, Gemini remembered that I had previously shared dmidecode
output, so it already knew my exact laptop specs. (Though it did include a note
about me being a "daily rice eater"—I assume it meant Linux 'ricing,' though I
actually use Debian Unstable, not Stable!).
The AI suggested starting with this prompt:
Read MEMORY.md and GEMINI.md. Based on my hardware, give me a shell script to
inspect my current GNOME environment so we can start replicating the session
basics.
How Did It Go?
I initialized a git repository for these files and instructed the Gemini CLI to
update GEMINI.md and commit changes after every major step so I could track
the progress.
The workflow looked like this:
Inspection: It created a script
to extract my GNOME settings.
Configuration: Once I provided the output, it began configuring Hyprland.
Utilities: It generated an installation script
for all required Wayland utilities.
Validation: All changes were staged in a hypr-config-draft folder. I
had Gemini verify them using hyprland --verify-config before moving them
to ~/.config/hypr.
Most things worked immediately, but I hit a snag with the wallpaper. Even after
generating the config, hyprpaper failed to display anything. The AI got
stuck in a loop trying to debug it. I eventually spawned a second Gemini CLI
instance to review the code and logs.
The debug log showed: 'DEBUG ]: Monitor eDP-1 has no target: no wp will be
created'.
It turns out the configuration format was outdated. By feeding the Hyprpaper
Wiki into the AI, it
finally corrected the config, and the wallpaper appeared.
After that, it successfully fixed an ssh-agent issue and configured a
clipboard manager with custom keybindings.
Learnings
I have used window managers for a long time because my hardware was rarely
top-of-the-line. However, I had moved back to KDE/GNOME with the arrival of
Wayland because most of my preferred WMs were X11-based.
Manually configuring a window manager is a painful, time-consuming process
involving endless wiki-trawling and trial-and-error. What usually takes weeks
took only a few hours with the Gemini CLI.
AI isn't perfect—I still had to step in and guide it when it hit a wall—but the
efficiency gain is undeniable. If you're interested in the configuration or the
history of the session, you can find the repository here.
I still have a few pending items in MEMORY.md, but I'll tackle those next
time!
When I wrote about the redhat logo in a shell prompt,
a commenter said it would be nice to achieve something similar for Debian, and
suggested "🍥" (U+1F365 FISH CAKE WITH SWIRL DESIGN) which, in some renderings,
looks to have a red swirl on top. This is not bad, but I thought we could do
better.
On Apple systems, the character "" (U+F8FF) displays as the corporate
Apple logo. That particular unicode code point is reserved: systems are free
to use it for something private and internal, but other systems won't use it
for the same thing. So if an Apple user tries to send a document with that
character in it to someone else, they won't see the Apple unless they are also
viewing it on an Apple computer. (Some folks use it for Klingon).
Nerd Font maps the Debian swirl logo to codepoints e77d, f306, ebc5 and
f08da (all of which are also in the Private Use Area). I've gone ahead and mapped
it to all those points but the last one (simply because I couldn't find it in FontForge.)
Note that, unless your recipients have this font, or the Nerd Font, or similar
set up, they aren't going to see the swirl. But enjoy it for private use. Getting
your system to actually use the font is, I'm afraid, left as an exercise for the
reader (but feel free to leave comments)
Thanks to mirabilos for chatting to me about this back in 2019. It's taken me
that long to get this blog post out of draft!
As an opportunity to rewire my brain from "docker" to "podman" and "buildah"
I started to create an image build with an ECH enabled curl at
https://gitlab.com/hoexter/ech.
Not sure if it helps anyone, but setup should be like this:
Hello world. I have been doing a lot after my internship with Outreachy. We are still working on some tasks :
I am working on running locales for my native language in live images.
I am also working on points to add to talk proposals for a Debian conference.
As I am moving around constantly, there are problems I had encountered when changing my networks. I had to connect my virtual machine to different networks and the network would not reflect within the machine. From terminal I edited the virtual machine XML settings:
su -
// input password
sudo virsh edit <machine_name> #its openqa for me
// Look for the interface within devices and replace this:
<interface type=&aposnetwork&apos>
<source network=&aposdefault&apos/>
#some other code in here
</interface>
// With just this then restart your machine:
<interface type=&aposuser&apos>
<model type=&aposvirtio&apos/>
</interface>
Hopefully the above will help someone out there. I am still working on a lot of tasks regarding the conference, so much to do and so little time. I am hoping I won’t get any burnout during this period. I won’t be updating much further till the conference. Have a nice time
The diffoscope maintainers are pleased to announce the release of diffoscope
version 314. This version includes the following changes:
[ Chris Lamb ]
* Don't run "test_code_is_black_clean" test in autopkgtests.
(Closes: #1130402)
[ Michael R. Crusoe ]
* Reformat using Black 26.1.0. (Closes: #1130073)










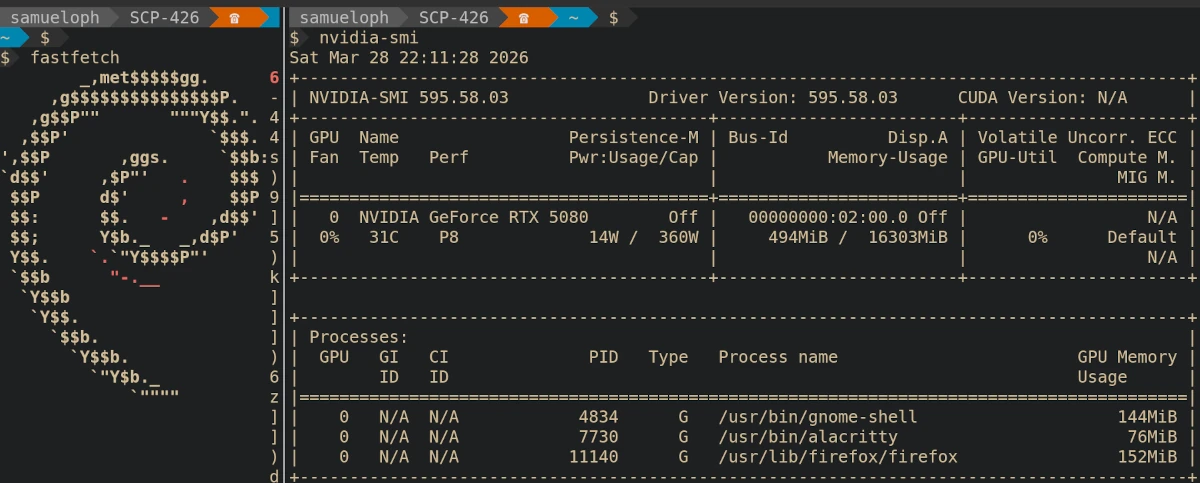



















 Image of the estimated qualiy of articles of the four articles in the second mixed-methods paper. Extreme dips reflect periods of frequent vandalism.
Image of the estimated qualiy of articles of the four articles in the second mixed-methods paper. Extreme dips reflect periods of frequent vandalism.