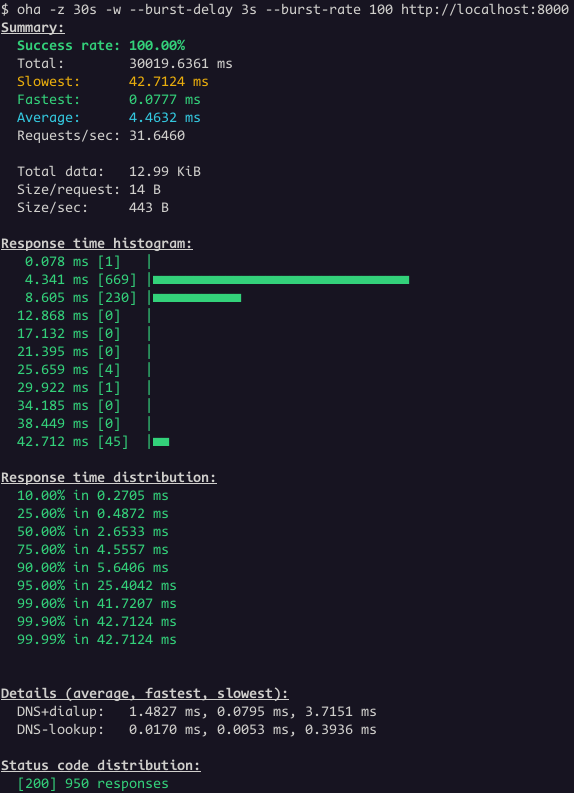
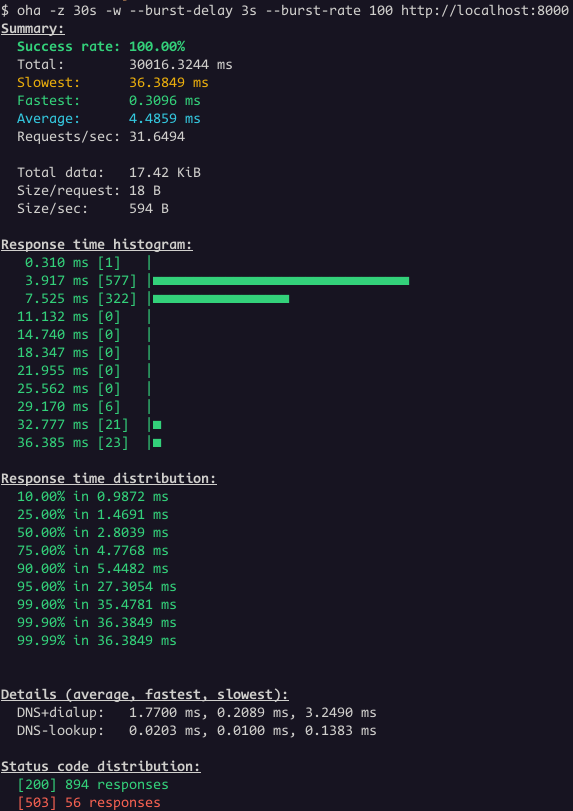
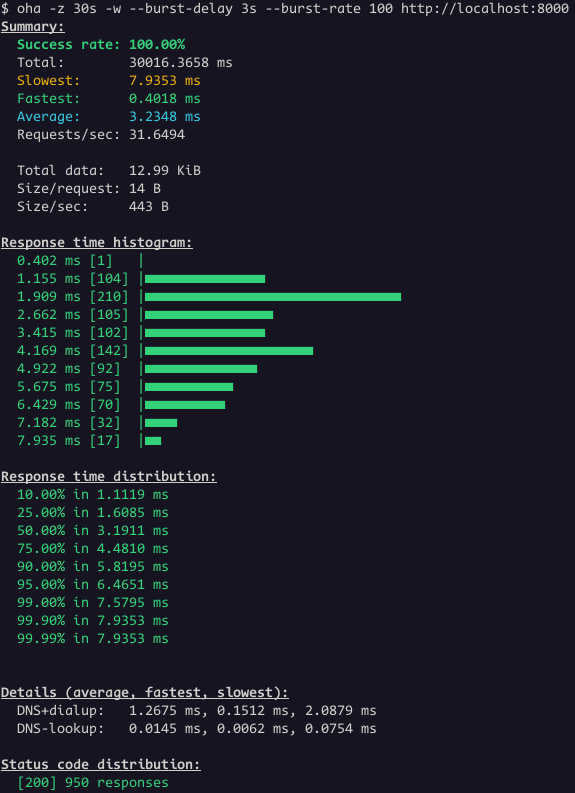
Wojciech Muła posted about modern perfect hashing for strings
and I wanted to make some comments about my own implementation (that sadly
never got productionized because doubling the speed compared to gperf
wasn't really that impactful in the end).
First, let's define the problem, just so we're all on the same page;
the goal is to create code that maps a known, fixed set of strings to a
predefined integer (per string), and rejects everything else.
This is essentially the same as a hash table, except that since the
set of strings is known ahead of time, we can do better than a normal
hash table. (So no “but I heard SwissTables uses SIMD and thus cannot
be beat”, please. :-) ) My use case is around a thousand strings or so,
and we'll assume that a couple of minutes of build time is OK (shorter
would be better, but we can probably cache somehow). If you've got
millions of strings, and you don't know them compile-time (for instance
because you want to use your hash table in the join phase of a database),
see this survey; it's a different
problem with largely different solutions.
Like Wojciech, I started splitting by length. This means that we can
drop all bounds checking after this, memcmp will be optimized by the
compiler to use SIMD if relevant, and so on.
But after that, he recommends using PEXT (bit extraction, from BMI2), which has
two problems: First, the resulting table can get quite big if your
input set isn't well-behaved. (You can do better than the greedy algorithm
he suggests, but not infinitely so, and finding the optimal mask quickly
is sort of annoying if you don't want to embed a SAT solver or something.)
Second, I needed the code to work on Arm, where you simply don't have this
instruction or anything like it available. (Also, not all x86 has it, and on
older Zen, it's slow.)
So, we need some other way, short of software emulation of PEXT (which
exists, but we'd like to do better), to convert a sparse set of bits
into a table without any collisions. It turns out the computer chess
community has needed to grapple with this for a long time (they want to
convert from “I have a \ on \ and there are pieces on
relevant squares \, give me an index that points to an array
of squares I can move to”), and their solution is to use… well,
magic. It turns out
that if you do something like ((value & mask) * magic), it is very
likely that the upper bits will be collision-free between your different
values if you try enough different numbers for magic. We can use this
too; for instance, here is code for all length-4 CSS keywords:
static const uint8_t table[] = {
6, 0, 0, 3, 2, 5, 9, 0, 0, 1, 0, 8, 7, 0, 0,
};
static const uint8_t strings[] = {
1, 0, 'z', 'o', 'o', 'm',
2, 0, 'c', 'l', 'i', 'p',
3, 0, 'f', 'i', 'l', 'l',
4, 0, 'l', 'e', 'f', 't',
5, 0, 'p', 'a', 'g', 'e',
6, 0, 's', 'i', 'z', 'e',
7, 0, 'f', 'l', 'e', 'x',
8, 0, 'f', 'o', 'n', 't',
9, 0, 'g', 'r', 'i', 'd',
10, 0, 'm', 'a', 's', 'k',
};
uint16_t block;
memcpy(&block, str + 0, sizeof(block));
uint32_t pos = uint32_t(block * 0x28400000U) >> 28;
const uint8_t *candidate = strings + 6 * table[pos];
if (memcmp(candidate + 2, str, 4) == 0) {
return candidate[0] + (candidate[1] << 8);
}
return 0;
There's a bit to unpack here; we read the first 16 bits from our value
with memcpy (big-endian users beware!), multiply it with the magic value 0x28400000U found by trial
and error, shift the top bits down, and now all of our ten candidate
values (“zoom”, “clip”, etc.) have different top four bits. We use that to index
into a small table, check that we got the right one instead of a random collision
(e.g. “abcd”, 0x6261, would get a value of 12, and table[12] is 7,
so we need to disambiguate that from “flex”, which is what we are actually looking
for in that spot), and then return the 16-bit identifier related to the match (or zero,
if we didn't find it).
We don't need to use the first 16 bits; we could have used any other
consecutive 16 bits, or any 32 bits, or any 64 bits, or possibly any of
those masked off, or even XOR of two different 32-bit sets if need be. My code
prefers smaller types because a) they tend to give smaller code size
(easier to load into registers, or can even be used as immediates),
and b) you can bruteforce them instead of doing random searches
(which, not the least, has the advantage that you can give up much quicker).
You also don't really need the intermediate table; if the fit is particularly good,
you can just index directly into the final result without wasting any
space. Here's the case for length-24 CSS keywords, where we happened to have
exactly 16 candidates and we found a magic giving a perfect (4-bit) value,
making it a no-brainer:
static const uint8_t strings[] = {
95, 0, 'b', 'o', 'r', 'd', 'e', 'r', '-', 'b', 'l', 'o', 'c', 'k', '-', 's', 't', 'a', 'r', 't', '-', 'w', 'i', 'd', 't', 'h',
40, 0, '-', 'w', 'e', 'b', 'k', 'i', 't', '-', 't', 'e', 'x', 't', '-', 'o', 'r', 'i', 'e', 'n', 't', 'a', 't', 'i', 'o', 'n',
115, 1, 's', 'c', 'r', 'o', 'l', 'l', '-', 'p', 'a', 'd', 'd', 'i', 'n', 'g', '-', 'b', 'l', 'o', 'c', 'k', '-', 'e', 'n', 'd',
198, 2, '-', 'w', 'e', 'b', 'k', 'i', 't', '-', 't', 'r', 'a', 'n', 's', 'f', 'o', 'r', 'm', '-', 'o', 'r', 'i', 'g', 'i', 'n',
225, 0, '-', 'i', 'n', 't', 'e', 'r', 'n', 'a', 'l', '-', 'o', 'v', 'e', 'r', 'f', 'l', 'o', 'w', '-', 'b', 'l', 'o', 'c', 'k',
101, 2, '-', 'w', 'e', 'b', 'k', 'i', 't', '-', 'b', 'o', 'r', 'd', 'e', 'r', '-', 'e', 'n', 'd', '-', 's', 't', 'y', 'l', 'e',
93, 0, 'b', 'o', 'r', 'd', 'e', 'r', '-', 'b', 'l', 'o', 'c', 'k', '-', 's', 't', 'a', 'r', 't', '-', 'c', 'o', 'l', 'o', 'r',
102, 2, '-', 'w', 'e', 'b', 'k', 'i', 't', '-', 'b', 'o', 'r', 'd', 'e', 'r', '-', 'e', 'n', 'd', '-', 'w', 'i', 'd', 't', 'h',
169, 1, 't', 'e', 'x', 't', '-', 'd', 'e', 'c', 'o', 'r', 'a', 't', 'i', 'o', 'n', '-', 's', 'k', 'i', 'p', '-', 'i', 'n', 'k',
156, 0, 'c', 'o', 'n', 't', 'a', 'i', 'n', '-', 'i', 'n', 't', 'r', 'i', 'n', 's', 'i', 'c', '-', 'h', 'e', 'i', 'g', 'h', 't',
201, 2, '-', 'w', 'e', 'b', 'k', 'i', 't', '-', 't', 'r', 'a', 'n', 's', 'i', 't', 'i', 'o', 'n', '-', 'd', 'e', 'l', 'a', 'y',
109, 1, 's', 'c', 'r', 'o', 'l', 'l', '-', 'm', 'a', 'r', 'g', 'i', 'n', '-', 'i', 'n', 'l', 'i', 'n', 'e', '-', 'e', 'n', 'd',
240, 0, '-', 'i', 'n', 't', 'e', 'r', 'n', 'a', 'l', '-', 'v', 'i', 's', 'i', 't', 'e', 'd', '-', 's', 't', 'r', 'o', 'k', 'e',
100, 2, '-', 'w', 'e', 'b', 'k', 'i', 't', '-', 'b', 'o', 'r', 'd', 'e', 'r', '-', 'e', 'n', 'd', '-', 'c', 'o', 'l', 'o', 'r',
94, 0, 'b', 'o', 'r', 'd', 'e', 'r', '-', 'b', 'l', 'o', 'c', 'k', '-', 's', 't', 'a', 'r', 't', '-', 's', 't', 'y', 'l', 'e',
196, 2, '-', 'w', 'e', 'b', 'k', 'i', 't', '-', 't', 'e', 'x', 't', '-', 's', 'i', 'z', 'e', '-', 'a', 'd', 'j', 'u', 's', 't',
};
uint32_t block;
memcpy(&block, str + 16, sizeof(block));
uint32_t pos = uint32_t(block * 0xe330a008U) >> 28;
const uint8_t *candidate = strings + 26 * pos;
if (memcmp(candidate + 2, str, 24) == 0) {
return candidate[0] + (candidate[1] << 8);
}
return 0;
You can see that we used a 32-bit value here (bytes 16 through 19
of the input), and a corresponding 32-bit magic (though still not
with an AND mask). So we got fairly lucky, but sometimes you do that.
Of course, we need to validate the entire 24-byte value even though
we only discriminated on four of the bytes! (Unless you know for sure
that you never have any out-of-distribution inputs, that is. There are
use cases where this is true.)
(If you wonder what 95, 0 or similar is above; that's just
“the answer the user wanted for that input”. It corresponds to
a 16-bit enum in the parser.)
If there are only a few values, we don't need any of this; just like
Wojciech, we do with a simple compare. Here's the generated code for
all length-37 CSS keywords, plain and simple:
if (memcmp(str, "-internal-inactive-list-box-selection", 37) == 0) {
return 171;
}
return 0;
(Again 171 is “the desired output for that input”, not a value the
code generator decides in any way.)
So how do we find these magic values? There's really only one way:
Try lots of different ones and see if they work. But there's a trick
to accelerate “see if they work”, which I also borrowed from computer
chess: The killer heuristic.
See, to try if a magic is good, you generally try to hash all the
different values and see if any two go into the same bucket. (If
they do, it's not a perfect hash and the entire point of the exercise
is gone.) But it turns out that most of the time, it's the same two
values that collide. So every couple hundred candidates, we check
which two values disproved the magic, and put those in a slot. Whenever
we check magics, we can now try those first, and more likely than not,
discard the candidate right away and move on to the next one (whether
it is by exhaustive search or randomness). It's actually a significant
speedup.
But occasionally, we simply cannot find a magic for a given group; either
there is none, or we didn't have enough time to scan through enough of the
64-bit space. At this point, Wojciech suggests we switch on one of the
characters (heuristically) to get smaller subgroups and try again.
I didn't actually find this to perform all that well; indirect branch
predictors are better than 20 years ago, but the pattern is typically
not that predictable. What I tried instead was to have more of a yes/no
on some character (i.e., a non-indirect branch), which makes for a coarser
split.
It's not at all obvious where the best split would be. You'd intuitively
think that 50/50 would be a good idea, but if you have e.g. 40 elements,
you'd much rather split them 32/8… if you can find perfect hashes for
both subgroups (5-bit and 3-bit, respectively). If not, a 20–20 split
is most likely better, since you very easily can find magics that put
20 elements into 32 buckets without collisions. I ended up basically
trying all the different splits and scoring them, but this makes the
searcher rather slow, and it means you basically must have some sort of
cache if you want to run it as part of your build system. This is the
part I'm by far the least happy about; gperf isn't great by modern
standards, but it never feels slow to run.
The end result for me was: Runtime about twice as fast as gperf,
compiled code about half as big. That's with everything hard-coded;
if you're pushed for space (or are icache-bound), you could make
more generic code at the expense of some speed.
So, if anyone wants to make a more modern gperf, I guess this space
is up for grabs? It's not exactly technology that will make your stock
go to AI levels, though.


 Comprehensive in-game tutorial
Comprehensive in-game tutorial There is a large ice flow world, but we are going underground now
There is a large ice flow world, but we are going underground now Good level design that you have to use to avoid those spiky enemies
Good level design that you have to use to avoid those spiky enemies The point where I had to pause the game, after missing those flying wigs 15 times in a row
The point where I had to pause the game, after missing those flying wigs 15 times in a row